前言 这个库在angular 中已经集成了,所以使用起来有良好的代码提示,但是在Vue中不行,一点提示都没有,下面的代码都在Vue项目中使用,以此分享自己在学习的体会:
一、初始RxJS (1)安装与导入 命令
按需导入:
import { Observer } from "rxjs";(2)Observable的工作 说明: Observable可以理解成被观察者 ,Observer就是观察者,连接两者的桥梁就是Observable对象的函数subscribe,同时RxJS中的数据流就是Observable对象,它实现了观察者模式和迭代器模式 ,这里聊聊前者。
=> 观察者模式 <= 解决问题: 它需要解决在一个持续产生事件的系统中,如何分割功能,让不同模块只需要处理一部分逻辑。
解决方法: 将逻辑分为发布者和观察者,发布者只管生产事件,之后将事件上注册一个观察者,至于事件如何被观察者处理它不关心;同样观察者只管将接收到的事件处理掉,不关心它是如何产生的。
与RxJS的联系: Observable对象就是一个发布者,通过函数subscribe将其与观察者Observer联系起来。
import { of } from "rxjs";
// of操作符会返回一个observable对象,将传入的内容依次发射出来;
// 此时scoure$就是一个发布者,它产生的事件就是三个整数
const scoure$ = of(1, 2, 3);
// 这里console.log作为观察者,将传给它的内容输出出来,
// 不管数据是怎么产生的
scoure$.subscribe(console.log);处理步骤:响应事件 :这是观察者的责任,也就是由subscribe的参数决定。 发布者如何关联观察者:也就是何时调用subscribe。 => 迭代器模式 <= 说明: 它提供一个通用的接口来遍历数据集合的对象,并且让使用者不用关心这个数据集合是如何实现的。从数据消费的角度,迭代器实现分为拉和推两种,简单理解就是拉取数据和推送数据,RxJS属于后者,它作为迭代器的使用者,并不需要主动去从Observable 中拉数据,而是只要subscribe上Observable对象之后,然后就能够收到消息的推送。
=> 创造Observable <= 执行过程: 创建一个Observable,也就是创建一个发布者,这个发布者接收一个onSubscribe用于与观察者产生联系,当发布者通过subscribe将其注册给观察者后,这个函数就会执行,函数的参数就是观察者对象,对这个对象的唯一要求就是需要存在next属性,属性的值是一个函数,用来接收传过来的数据
// 0.用于定义发布者
import { Observable } from "rxjs";
// 4.触发后这个函数的参数是观察者的一个包装,
// 它与观察者并不等价
const onSubscribe = (observer) => {
observer.next(1);
observer.next (2);
observer.next(3);
};
// 1.这里创建一个发布者,它存在一个onSubscribe函数与
// 观察者产生联系
const source$ = new Observable(onSubscribe);
// 2.创建一个观察者,有一个next属性用于接收传过来的值
const theObserver = {
next: (item) => console.log(item),
};
// 3.通过subscribe函数 将发布者和观察者联系起来,此时发
// 布者中的onSubscribe函数会被触发
source$.subscribe(theObserver);
=> 延迟的Observable <= 举例: 如何让上面的例子中推送每个正整数之间有一定的时间间隔?
思考: 这个逻辑放在哪个部分更合适?
解释: 按照分工,发布者产生数据,观察者处理数据,这样一来发布者控制推送数据的节奏也很合理。
const onSubscribe = (observer) => {
let number = 1;
const handle = setInterval(() => {
observer.next(number++);
if (number > 3) {
clearInterval(handle);
}
}, 1000);
};结论: 发布者推送数据可以有时间间隔,这样使得异步操作十分容易,因为对于观察者,只需要被动接受推送数据来处理,再不用关心数据何时产生。
=> 永无止境的Observable <= 说明: 其实发布者发射的数据可以是无穷的,每次发布者使用next发射出一个数据,这个数据会被观察者接收然后消化掉,所以不会存在数据堆积;如果发布者的next方法停止调用,只能表示发布者此时不会发射数据出去,但并不代表之后不会发射数据;如果需要明确发布就不会再有新数据产生了,还需要多个Observable完结的方式 。
const onSubscribe = (observer) => {
let number = 1;
const handle = setInterval(() => {
observer.next(number++);
}, 1000);
};=> Observable的完结 <= 说明: 观察者的next 方法只能表示现在推送的数据是什么,并不能表示后面没有更多数据了,也就是没办法完全停止 它推送数据,但是在RxJS中,可以使用观察者的complete 方法来完成。
import { Observable } from "rxjs";
const onSubscribe = (observer) => {
let number = 1;
const handle = setInterval(() => {
observer.next(number++);
if (number > 3) {
clearInterval(handle);
// 使用函数完全停止数据的发送
observer.complete();
}
}, 1000);
};
const source$ = new Observable(onSubscribe);
const theObserver = {
next: (item) => console.log(item),
// 定义函数来让发布者完全停止数据的传输
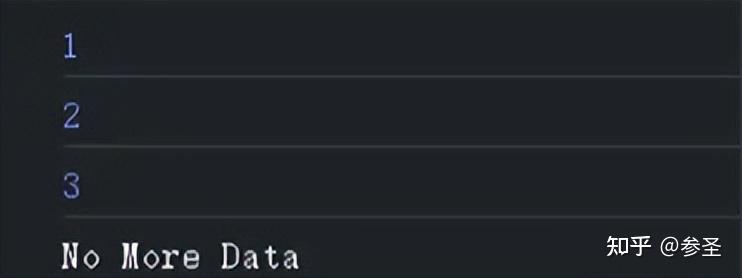
complete: () => console.log("No More Data"),
};
source$.subscribe(theObserver);
=> 错误的Observable <= 说明: 理想情况下,发布者只管生产数据给观察者来消耗,但是,难免有时候发布者会遇到了异常情况,而且这种异常情况不是生产者所能够处理并恢复正常的,发布者在这时候没法再正常工作了,就需要通知对应的观察者发生了这个异常情况,如果只是简单地调用 complete,观察者只会知道没有更多数据,却不知道没有更多数据的原因是因为遭遇了异常,所以,我们还要在发布者和观察者的交流渠道中增加一个新的函数error。
import { Observable } from "rxjs/Observable";
const onSubscribe = (observer) => {
observer.next(1);
// 此时发布者出现不能自己解决的错误,调用方法通知观察者,
// 此时发布者已经进入完结的状态,后面所调用的next和complete
// 都会失效
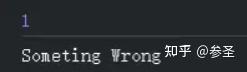
observer.error("Someting Wrong");
observer.complete();
};
const source$ = new Observable(onSubscribe);
const theObserver = {
next: (item) => console.log(item),
// 用来处理错误信息
error: (err) => console.log(err),
complete: () => console.log("No More Data"),
};
source$.subscribe(theObserver);在RxJS中,一个发布者对象只有一种终结状态,要么是complete,要么是error,一旦进入出错状态,这个发布者对象也就终结了,再不会调用对应观察者的next函数 ,也不会再调用观察者的complete函数 ;同样,如果一个发布者对象进入了完结状态,也不能再调用观察者的next和error。 (3)退订Observable 说明: 有时候需要断开发布者与观察者之间的联系,这个操作就叫做退订,在发布者的onSubscribe函数执行的时候,它可以返回一个对象,对象上可以有一个unsubscribe函数,执行这个函数来进行退订操作。
import { Observable } from "rxjs";
const onSubscribe = (observer) => {
let number = 1;
const handle = setInterval(() => {
observer.next(number++);
}, 1000);
return {
unsubscribe : () => {
clearInterval(handle);
},
};
};
const source$ = new Observable(onSubscribe);
const subscription = source$.subscribe((item) => console.log(item));
setTimeout(() => {
subscription.unsubscribe();
}, 3500);注意: 退订函数执行后,表示观察者不再接受发布者推送的数据,但是发布者并没有停止推送数据,因为发布者并没有到达终结状态 ,也就是没有调用complete 或者是error 方法,此时只是发布者推送的数据观察者不接收而已,看下面的例子:
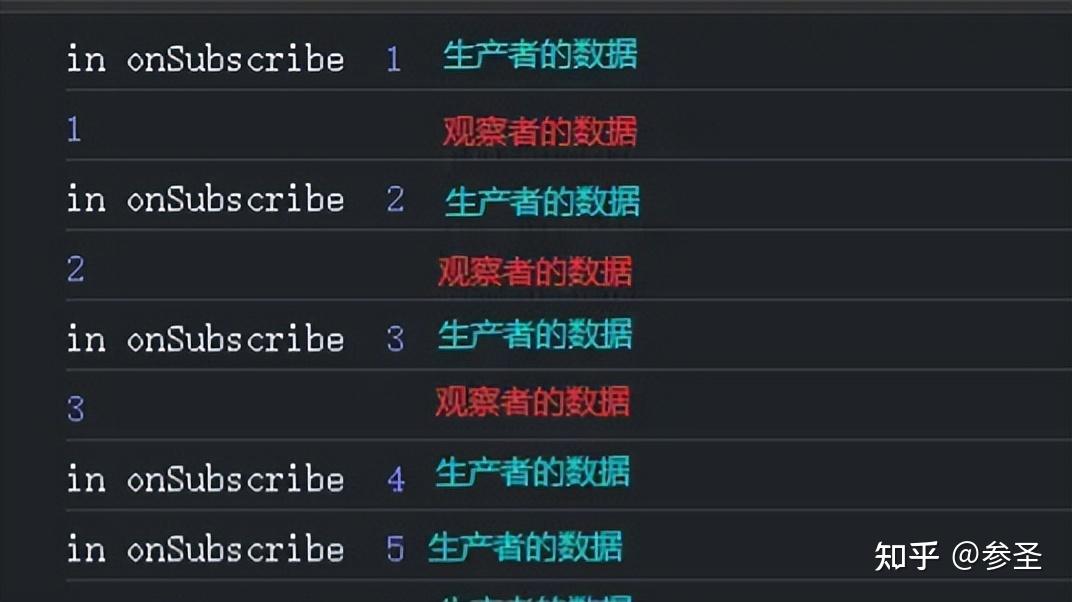
import { Observable } from "rxjs";
const onSubscribe = (observer) => {
let number = 1;
const handle = setInterval(() => {
// 将发布者发射的数据打印出来
console.log("in onSubscribe ", number);
observer.next(number++);
}, 1000);
return {
unsubscribe: () => {
// 这里不清除定时器,让发布者继续产生数据
// clearInterval(handle);
},
};
};
const source$ = new Observable(onSubscribe);
// 每次观察者执行的时候打印出收到的数据
const subscription = source$.subscribe((item) => console.log(item));
setTimeout(() => {
subscription.unsubscribe();
}, 3500);发布者产生的事件,只有观察者通过订阅之后才会收到,在退订之后就不会收到。 (4)了解两种Observable 说明: 这里介绍的是Hot Observable和Cold Observable。
场景: 假设每个发布者对象有两个观察者对象来订阅, 而且这两个观察者对象并不是同时订阅,第一个观察者对象订阅N秒钟之后,第二个观察者对象才订阅同一个发布者对象,而且,在这N秒钟之内,发布者对象已经吐出了一些数据,此时对这吐出的数据有两种处理:
Hot Observable:只需要接受从订阅那一刻开始发布者产生的数据就行;有点类似在电视上面看节目,你所看到的内容是节目当前这一刻开始的,之前的节目你是看不见的,假如你的家人跟你一起看,那么你们看到的节目是一样的,这就可以理解为获取数据的数据源是相同的 Cold Observable:不能错过,需要获取发布者之前产生的数据,也就是每次都需要获取发布者完整的数据,可以理解为每次得到的数据与之前的数据之间并不存在联系,是相互独立的,也就是每次会得到独立的数据源,就像你在手机应用市场下载游戏,跟你在同样地方下载的游戏是一样的。 理解: 那么就可以得到这样的结果,如果Cold Observable没有订阅者,数据不会真正的产生,就像你如果不主动下载游戏,你手机上不可能玩到的;而对于Hot Observable在没有订阅者的时候,数据依然产生,只不过不传入数据管道而已,就像电视机节目,节目一直存在与此,只是你没切换到那个频道观看而已。
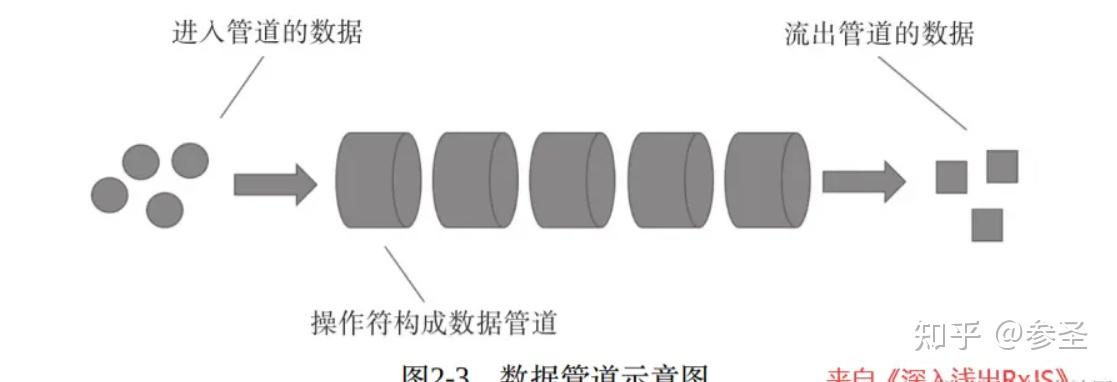
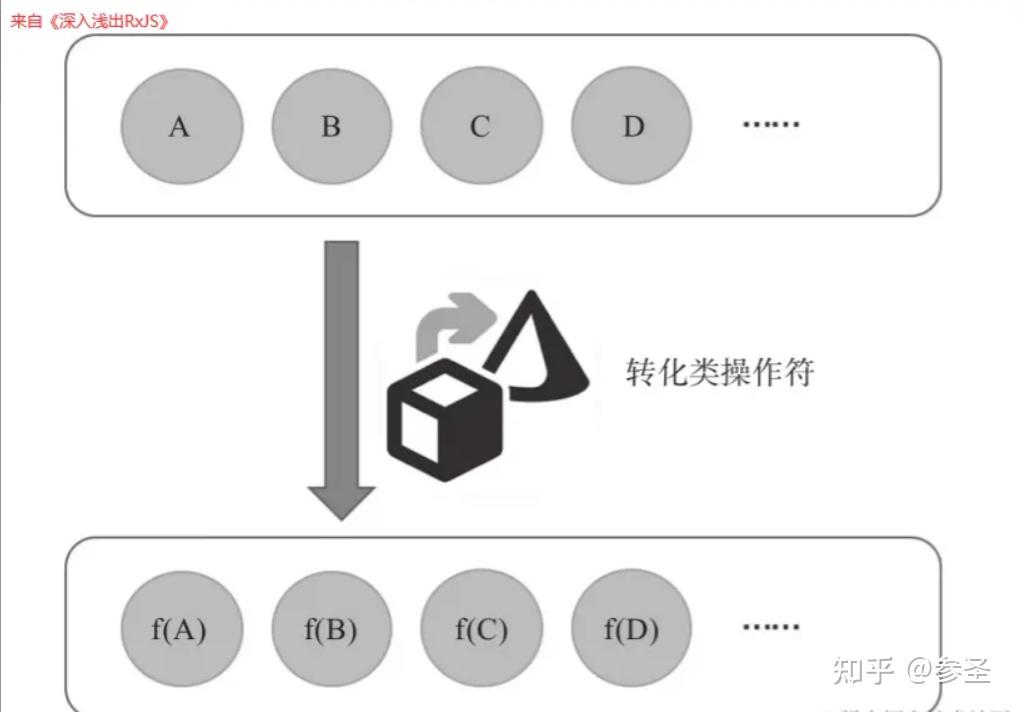
(5)操作符简介 说明: 一个发布者对象就是一个数据流,在RxJS中数据流一般使用$开头来命名;在一个复杂问题里面,数据流并不会直接交给观察者来处理,在这途中会使用一系列内置的函数来处理数据,这些函数可以理解为操作符;就像一个管道,数据从管道的一段流入,途径管道各个环节,当数据到达观察者的时候,已经被管道操作过,有的数据已经被中途过滤抛弃掉了,有的数据已经被改变了原来的形态,而且最后的数据可能来自多个数据源,最后观察者只需要处理能够达到终点的数据。
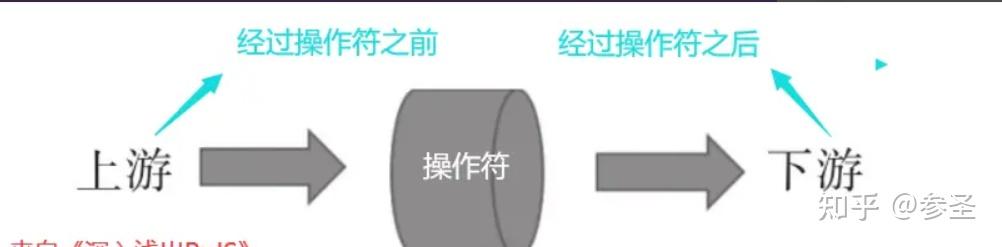
说明: 在数据管道中流淌的数据就像是水,从上游流向下游。对一个操作符来说,上游可能是一个数据源,也可能是其他操作符,下游可能是最终的观察者,也可能是另一个操作符,每一个操作符之间都是独立的,正因为如此,所以可以对操作符进行任意组合,从而产生各种功能的数据管道。
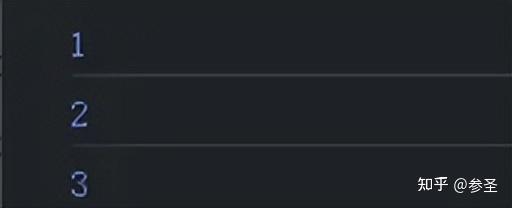
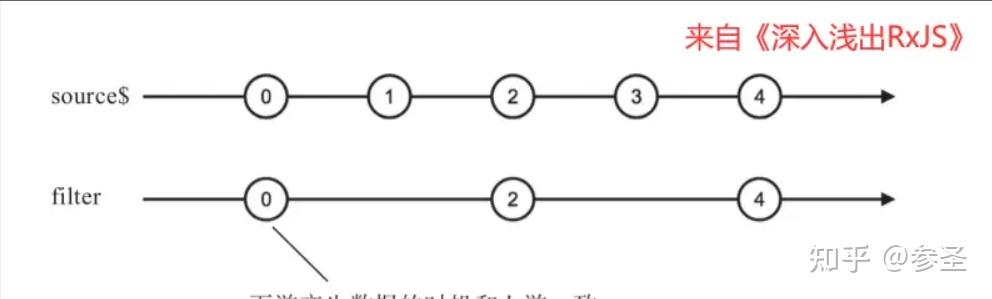
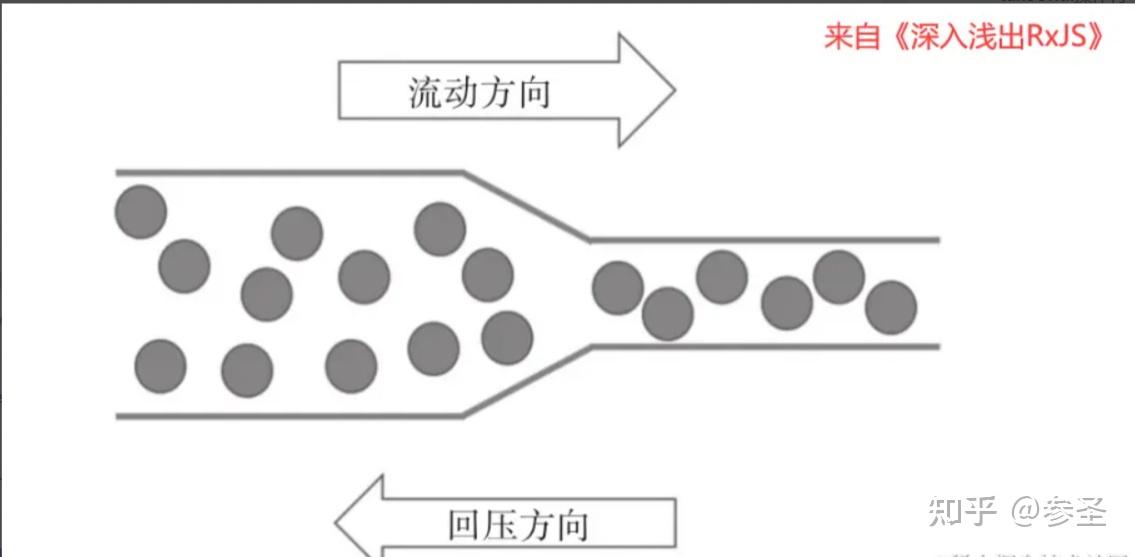
6)理解弹珠图 作用: RxJS中每一个发布者是一个数据流,简单的数据流可以由大脑想象出来,但是复杂的可就不好像了,此时就可以使用弹珠图 来具体的方式来描述数据流,看两张图:
说明: 这个弹珠图所表示的数据流,每间隔一段时间吐出一个递增的正整数,吐出到3的时候结束。因为每一个吐出来的数据都像是一个弹珠,所以这种表达方式叫做弹珠图。在弹珠图中,每个弹珠之间的间隔,代表的是吐出数据之间的时间间隔,通过这种形式,能够很形象地看清楚每个发布者对象中数据的分布。 根据弹珠图的传统,竖杠符号|代表的是数据流的完结,对应调用complete函数,数据流吐出数据3之后立刻就完结了。 符号×代表数据流中的异常,对应于调用下游的error函数。
注意: 为了描述操作符的功能,弹珠图中往往会出现多条时间轴,因为各部分操作符的工作都是把上游的数据转为传给下游的数据,在弹珠图上必须把上下游的数据流都展现出来,此外,编写弹珠图可以去此处,后面如果存在弹珠图的地方所使用的代码复制到此处就可以看到了。
二、实现操作符 理解: 一个操作符是返回一个Observable对象的函数,不过,有的操作符是根据其他Observable对象产生返回的Observable对象,有的操作符则是利用其他类型输出产生返回的Observable对象,还有一些操作符不需要输出就可以凭空创造一个Observable对象,这里以实现一个操作符来慢慢理解什么是操作符。
(1)实现操作符函数 说明: 每一个操作符是一个函数,不管函数的功能是怎样的,它需要包含以下功能点,这里实现map操作符为例
返回⼀个全新的Observable对象。 需要存在订阅和退订的操作。 处理异常情况。 及时释放资源。 => 返回Observable对象 <= 分析: 首先map操作符的功能是遍历得到的数据,通过传入的参数函数来处理这些数据,看下面的例子:
// 这里的函数参数将数据的每一个值都乘以2,
// 如果source$是⼀个 1、2、3的序列,
// 那么map返回的序列就是2、4、6,根据函数式编程 的原则,
// map函数是不会修改原始的数据的,同时其返回值是⼀个全
// 新的Observable对象,这样可以保持原始Observable对象的状态
// 避免不可预料的行为
const result$ = source$.map(x => x * 2);实现: 根据上面的分析可以得到下面这个函数
// 这里的project就是传递给map操作符的函数参数
function map(project) {
// map中利⽤new关键字创造了⼀个Observable对象,
// 函数返回的结果就是这个对象,如此⼀来,
// map可以⽤于链式调⽤,可以在后⾯调⽤其他的操作符,
// 或者调⽤subscribe增加Observer。
return new Observable((observer) => {
// 假设此处this表示发布者对象,订阅后数据就会交给观察者了
this.subscribe({
next: (value) => observer.next(project(value)),
error: (err) => observer.error(error),
complete: () => observer.complete(),
});
});
}=> 退订处理 <= 说明: 作为一个通用的操作符,无法预料上游Observable是如何实现的,上游完全可能在被订阅时分配了特殊资源,如果不明确地告诉上游这些资源再也用不着了的话,它也不会释放这些资源,此时就会造成资源的泄露,所以下游退订那些资源,就要告诉上游退订那些资源。
function map(project) {
return new Observable((observer) => {
const sub = this.subscribe({
next: (value) => observer.next(project(value)),
error: (err) => observer.error(error),
complete: () => observer.complete(),
});
return {
// 根据前面的了解这里需要存在一个unsubscribe
// 方法用于退订
unsubscribe: () => {
sub.unsubscribe();
},
};
});
}=> 处理异常 <= 说明: 上面代码中的参数project可以输入的情况有很多,可能存在执行的时候不合理的代码,此时就会出现异常,此时需要 捕获异常错误,把异常错误沿着数据流往下游传递,最终如何处理交给观察者来决定。
function map(project) {
return new Observable((observer) => {
const sub = this.subscribe({
next: (value) => {
try {
observer.next(project(value));
} catch (err) {
observer.error(err);
}
},
error: (err) => observer.error(error),
complete: () => observer.complete(),
});
return {
unsubscribe: () => {
sub.unsubscribe();
},
};
});
}(2)关联Observable 使用原型: 这个操作符在使用的时候需要一个Observable对象实例,因此这个操作符是一个实例操作符,此时使用打补丁的方式关联发布者对象的格式为Observable.prototype.操作符 = 操作符函数,既然有实例操作符,当然也有静态操作符,它不需要Observable实例就可以使用,它的打补丁的格式为Observable.操作符 = 操作符函数,这个的弊端在于会影响每一个Observable对象。
Observable.prototype.map = map;使用call和bind: 解决上面的问题,可以让我们⾃定义的操作符只对指定的 Observable对象可⽤,这时就可以⽤bind ,当然也可以使用call 。
// 一般使用
const result$ = map.bind(Observable对象)(x => x * 2);
// 链式调用
const result$ = map.bind(
map.bind(Observable对象)((x) => x * 2)
)((x) => x + 1);
// 一般使用
onst result$ = map.call(Observable对象, x => x * 2);
// 链式调用
const result$ = map.call(
map.call(Observable对象, (x) => x * 2),
(x) => x * 2
);3)改进操作符 说明: 如果遵循函数式编程思想,需要使用纯函数,也就是函数执行的结果完全由输入的参数决定,但是上面定义的函数中存在this,这是一个不确定的因素,也就是这个函数不属于纯函数了,所以在此处需要改进一下。
=> 缺陷 <= 说明: 在现代网页开发的过程中,都会经过打包才发布到产品环境,在打包的过程中会使用Tree-Shaking这个工具来去除代码中没有使用的代码,比如那些引入的变量但是并没有使用这种的;但是这个工具对于RxJS来说没什么用,这是因为Tree Shaking只能做静态代码检查,并不是在程序运行时去检测这个函数是否被真的调用,只有这个函数在任何代码中间都没有引用过,才认为这个函数不会被引用。然而,RxJS中任何一个操作符都是挂在 Observable类上或者Observable.prototype上的,赋值给Observable或者 Observable.prototype上某个属性在Tree Shaking看来就是被引用,所以,所有的操作符,不管真实运用时是否被调用,都会被Tree Shaking认为是会用到的代码,也就不会当做死代码删除;其次上面关联Observable的方式是直接添加到其原型上面,由于全局存在一个Observable对象,就跟window对象一样,像上面添加属性和方法是不可取的,是会带来隐患的。
=> 不"打补丁" <= 说明: 开发RxJS库的规则的其中一条就是不能使用打补丁的方式使操作符函数与Observable对象关联起来。如果是实例操作符,可以使用前面介绍过的bind/call,让一个操作符函数只对一个具体的Observable对象生效;如果是静态操作符,直接使用就好。
// 这里使用上面实现的map函数实现一个double操作符
import { Observable, of } from "rxjs";
function map(project) {
return new Observable((observer) => {
const sub = this.subscribe({
next: (value) => {
try {
observer.next(project(value));
} catch (err) {
observer.error(err);
}
},
error: (err) => observer.error(error),
complete: () => observer.complete(),
});
return {
unsubscribe: () => {
sub.unsubscribe();
},
};
});
}
Observable.prototype.double = function () {
// 将当前的Observable对象作为this值传递给map函数
return map.call(this, (x) => x * 2);
};
// of操作符用于创建一个Observable对象
const source$ = of(1, 2, 3);
const result$ = source$.double().subscribe((res) => console.log(res));(4)lettable/pipeable操作符 原因: 上面使用call/bind方法在函数体内还是会使用this,函数还是不纯,其次call的返回类型是无法确定的,在ts中只能使用any表示,因此会让其失去类型检查。
说明: 从RxJS v5.5.0开始,加上了这种更先进的操作符定义和使用方式,称为pipeable操作符,也曾经被称为lettable操作符,但是因为字面上太难理解,所以改成pipeable。
=> let操作符 <= 作用: 实际上就是把上游的Observable对象作为参数传递给let操作符里面的参数进行处理,处理完之后将返回的Observable交给下游来订阅。
// 下面的map函数就是上面写的那个,这是以前的写法,现在不支持,
import {Observable} from 'rxjs/Observable';
import 'rxjs/add/observable/of';
import 'rxjs/add/operator/map';
import 'rxjs/add/operator/let';
const source$ = Observable.of(1, 2, 3);
// 虽然map的使⽤是通过给Observable打补丁导⼊的,
// 但是map是直接作⽤于参数obs$,⽽不是作⽤于this,
// 所以,double$是⼀个纯函数。
const double$ = obs$ => obs$.map(x => x * 2);
// let的参数是⼀个函数,在这个例⼦中函数参数名为double$,
// 这个函数名也以$为后缀,代表它返回的是⼀个Observable对象,
// double$同样接受⼀个Observable对象作为输⼊参数,也就是说,
// double$的功能就是根据⼀个Observable对象产⽣⼀个新的
// Observable对象。
const result$ = source$.let(double$);过程: let起到连接上游下游 的作用,真正的工作完全由函数参数map来执行。
处理之前的map函数: 此时map的实现部分也看不到对this的访问,而是用一个参数obs$代替了 this,这样,在数据管道中上游的Observable是以参数形式传递,而不是靠 this来获得,让map彻底成了一个纯函数。map执行返回的结果是一个函数,接受一个Observable对象返回一个 Observable 对象,正好满足let的参数要求。
const map = (fn) => (obs$) =>
new Observable((observer) =>
obs$.subscribe({
next: (value) => observer.next(fn(value)),
error: (err) => observer.error(error),
complete: () => observer.complete(),
})
);好处: 由于每一个lettable操作符都是纯函数,而且也不会被作为补丁挂在Observable上,Tree Shaking就能够找到根本不会被使用的操作符。
=> pipe操作符 <= 原因: 要导入let这个操作符,又不得不用传统的打补丁或者使用call的方式,使用起来要导入很麻烦;所以创建了pipe操作符,它可以满足let具备的功能。使用pipe只需像使用let那样导入模块,任何Observable对象都保持pipe,此外还有管道功能,可以把多个lettable操作符串接起来,形成数据管道。
import { map, filter, of } from "rxjs";
const source$ = of(1, 2, 3);
// 可以一次使用多个操作符
const result$ = source$.pipe(
filter((x) => x % 2 === 0),
map((x) => x * 2)
);
result$.subscribe(console.log);三、创建数据流 (1)创建类操作符 说明: 这里所说的创造,是指这些操作符不依赖于其他Observable对象,这些操作符可以凭空或者根据其他数据源创造出⼀个Observable对象,其次创建类操作符往往不会从其他Observable对象获取数据,因为在数据管道中它自己就是数据流的源头,基于这些特性大部分的创建类操作符都是静态操作符。
(2)创建同步数据流 说明: 对于同步的Observable对象,需要关心的是存在哪些数据和数据之间的先后顺序,由于数据之间的时间间隔不存在因此不需要考虑时间方面的问题。
=> of操作符 <= 作用: 可以轻松创建指定数据集合的Observable对象;
参数: of(数据1,数据2,数据3...);
注意: of操作符所产生的Observable对象被订阅后会将参数依次吐出来,吐完之后会调用complete方法;吐的这个过程是同步的,也就是所有数据之间是不存在间隔的。
const { of } = Rx;
of(1).pipe();const { of } = Rx;
of(1, 2, 3).pipe();
值: of产生的是Cold Observable,对于每一个Observer都会重复吐出同样的一组数据,所以可以反复使用。
=> range操作符 <= 作用: 对需要产生多个很长连续数字序列的场景,就是得上range这个操作符了,range的含义就是“范围”,只需要指定一个范围的开始值和长度,range 就能够产生这个范围内的依次+1的数字序列;同样数据吐完之后会调用complete方法。
参数: range(序列开始的任意数字,序列的长度)
const { range } = Rx;
range(1, 100).pipe();局限性: 无法规定每次递增的大小
=> generate操作符 <= 作用: 类似一个for循环,设定一个初始值,每次递增这个值,直到满足某个条件的时候才中止循环,同时,循环体内可以根据当前值产生数据。
参数: generate(初始值, 条件判断函数, 值如何增加函数, 返回结果处理函数)
// 假设存在这样的for循环:产⽣⼀个⽐10⼩的所有偶数的平⽅
const result = [];
for (let i = 2; i < 10; i += 2) {
result.push(i * i);
}
// 使用generate类似实现
const { generate } = Rx;
generate(
2, // 初始值,相当于for循环中的i=2
value => value < 10, //继续的条件,相当于for中的条件判断
value => value + 2, //每次值的递增
value => value * value // 产⽣的结果
).pipe();注意: 使用时需要保证后面三个函数参数为纯函数
=> repeat操作符 <= 作用: 重复上游Observable中的数据n 次
参数1: repeat(重复的次数)
const { of } = Rx;
const { repeat } = RxOperators;
of(1, 2, 3).pipe(repeat(100))参数2: repeat({count: 重复的次数, delay: 数据的时间间隔})
import { of, repeat } from "rxjs";
of(1, 2, 3)
.pipe(
repeat({
count: 10,
delay: 1000,
})
)
.subscribe((res) => console.log(res));注意: 保证上游Observable对象一定会完结。
=> EMPTY常量 <= 作用: 产生一个直接完结 的Observable对象,没有参数,不产生任何数据,直接完结。
const { EMPTY } = Rx;
EMPTY.pipe()
=> throwError操作符 <= 作用: 它所产生的Observable对象也是什么都不做,直接出错 ,抛出的错误就是throw的参数
参数: throwError(错误程序)
const { throwError } = Rx;
throwError(new Error('这是一个错误')).pipe()
=> NEVER常量 <= 作用: 产生的Observable对象就真的是什么都不做,既不吐出数据,也不完结 ,也不产生错误 ,就这样待着,一直到永远
const { NEVER } = Rx;
NEVER.pipe()
(3)创建异步数据流 说明: 就是创建异步的Observable对象,不光要考虑产生什么数据,还需要考虑数据之间的时间间隔了
=> interval操作符 <= 作用: 定时从Observable对象吐出一个数据,如果不主动结束就一直执行
参数: interval(吐数据的间隔毫秒数)
const { interval } = Rx;
interval(1000).pipe()注意: => timer操作符 <= 作用: 产生的Observable对象在指定毫秒之后会吐出一个数据,执行后立即结束
参数: timer(毫秒数 / 一个Date对象, 时间间隔)
// 明确延时产⽣数据的时间间隔
const { timer } = Rx;
timer(1000).pipe()// 明确的是⼀个时间点
const { timer } = Rx;
timer(
new Date(
new Date().getTime() + 1000
)
).pipe()const { timer } = Rx;
timer(1000,2000).pipe()注意: => from操作符 <= 作用: 以把任何可迭代对象都转化为Observable对象
参数: from(任何可迭代对象)
const { from } = Rx;
from([1,2,3]).pipe()const { from } = Rx;
from('abc').pipe()注意: 在from的眼中,把输出参数都当做一个Iterable 来看待,所以上面的字符串abc在from看来就和数组['a','b','c']没有区别
import { from } from "rxjs";
const promise = Promise.resolve("good");
const source$ = from(promise);
source$.subscribe(
console.log,
(error) => console.log("catch", error),
() => console.log("complete")
);import { from } from "rxjs";
const promise = Promise.reject("error");
const source$ = from(promise);
source$.subscribe(
console.log,
(error) => console.log("catch", error),
() => console.log("complete")
);解释: 如果from的参数是promise,当promsie成功结束,from产生的Observable对象就会吐出Promise成功的结果,并且立刻结束,如果以失败而告终的时候,from产生的Observable对象也会立刻产生失败事件
=> fromEvent操作符 <= 作用1: 在网页开发中,可以把DOM中的事件转化为Observable对象中的数据
参数1: fromEvent(事件源, 事件名称)
// 希望点击id为clickMe的按钮时,id为text的div中的数字会增加1,
// 连续点击那个按钮,对应数字会持续增加
<template>
<div>
<button id="clickMe">Click Me</button>
<div id="text">0</div>
</div>
</template>
<script setup>
import { fromEvent } from "rxjs";
import { onMounted } from "vue";
let clickCount = 0;
onMounted(() => {
const event$ = fromEvent(
document.querySelector("#clickMe"),
"click"
);
event$.subscribe(() => {
document
.querySelector("#text")
.innerText = ++clickCount;
});
});
</script>
<style></style>说明: 网页开发中事件源一般是DOM节点
// 这里展示从Node.js的events中获得数据
import { fromEvent } from "rxjs";
// 这个模块需要使用 npm i events 安装一下
import EventEmitter from "events";
const emitter = new EventEmitter();
// 只接受数据源中事件为"msg"的数据
const source$ = fromEvent(emitter, "msg");
source$.subscribe(
console.log,
(error) => console.log("catch", error),
() => console.log("complete")
);
// emitter的emit函数发送任何名称的事件,
// 第⼀个参数就是事件名称,第⼆个参数是数据
emitter.emit("msg", 1);
emitter.emit("msg", 2);
emitter.emit("another-msg", "oops");
emitter.emit("msg", 3);注意: fromEvent产生的是Hot Observable,也就是数据的产生和订阅是无关的,如果在订阅之前调用emitter.emit,那有没有Observer这些数据都会立刻吐出来,等不到订阅的时候,当添加了Observer的时候,仍然什么数据都获得不到。
import { fromEvent } from "rxjs";
import EventEmitter from "events";
const emitter = new EventEmitter();
const source$ = fromEvent(emitter, "msg");
// 在订阅之前发射数据
emitter.emit("msg", 1);
emitter.emit("msg", 2);
emitter.emit("another-msg", "oops");
emitter.emit("msg", 3);
source$.subscribe(
console.log,
(error) => console.log("catch", error),
() => console.log("complete")
);
=> fromEventPattern操作符 <= 作用: 用于处理的Observable对象被订阅 和退订 时的动作
参数: fromEventPattern(被订阅时触发的函数, 被退订时触发的函数)
import { fromEventPattern } from "rxjs";
import EventEmitter from "events";
const emitter = new EventEmitter();
// handler参数可以理解为观察者对象中的next方法
const addHandler = (handler) => {
// 监听事件源中的msg事件,每次触发事件执行next方法
emitter.addListener("msg", handler);
};
const removeHandler = (handler) => {
// 与上面相反,会移除msg事件上面的next方法
emitter.removeListener("msg", handler);
};
const source$ = fromEventPattern(addHandler, removeHandler);
const subscription = source$.subscribe(
console.log,
(error) => console.log("catch", error),
() => console.log("complete")
);
emitter.emit("msg", "hello");
emitter.emit("msg", "world");
// 取消订阅后emitter上面监听的事件被取消掉,
// 所以此处的值并不会出现在Observable对象里面
subscription.unsubscribe();
emitter.emit("msg", "end");说明: 它提供的就是一种模式,不管数据源是怎样的行为,最后的产出都是一个Observable对象
=> ajax操作符 <= 作用: 用于发送请求并根据结果返回Observable对象
参数: ajax('请求的地址')
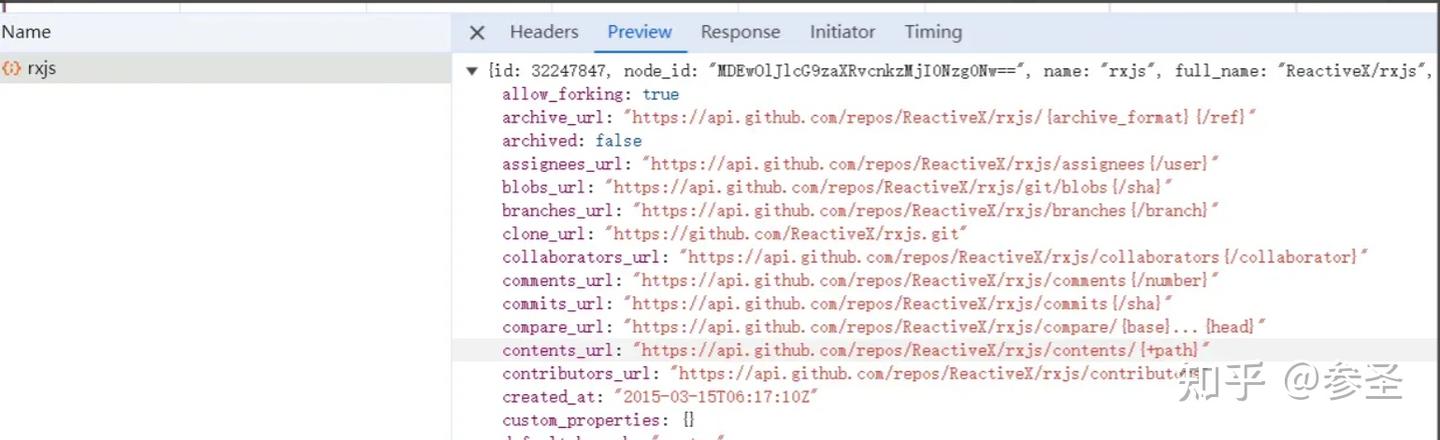
// 根据github上的api获取RxJS项⽬获得的Start的数量
<template>
<div>
<button id="getStar">Get RxJS Star Count</button>
<div id="text"></div>
</div>
</template>
<script setup>
import { onMounted } from "vue";
import { fromEvent } from "rxjs";
import { ajax } from "rxjs/ajax";
onMounted(() => {
fromEvent(
document.querySelector("#getStar"),
"click"
).subscribe(
() => {
ajax("https://api.github.com/repos/ReactiveX/rxjs")
.subscribe(
(value) => {
const starCount =
value.response.stargazers_count;
document.querySelector("#text").innerText =
starCount;
});
});
});
</script>
=> defer操作符 <= 作用: 用于延迟 执行某些操作
参数: defer(一个函数,这个函数会在被订阅时调用)
// 延迟发送请求
import { defer } from "rxjs";
import { ajax } from "rxjs/ajax";
defer(
() => ajax("https://api.github.com/repos/ReactiveX/rxjs")
.subscribe(
(res) => console.log(res)
)
);
四、合并数据流 (1)合并类操作符 说明: 其作用在于将有多个Observable对象作为数据来源,把不同来源的数据根据不同的规则合并到一个Observable对象中。
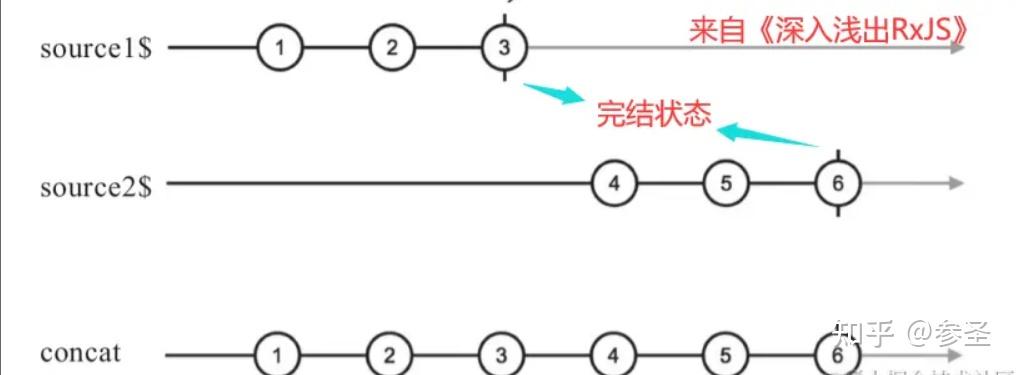
=> concat操作符 <= 作用: 把多个Observable中的数据内容依次合并,合并的时候原有数据不变
参数: concat(数据1, 数据2, 数据3...)
import { concat, of } from "rxjs";
const source1$ = of(1, 2, 3);
const source2$ = of(4, 5, 6);
concat(source1$, source2$)
.subscribe(
(res) => console.log(res)
);注意: 它在工作的时候,会先从第一个Observable对象中获取数据,等它complete之后,再从下一个对象中去数据,直到取完所有的,此时,如果其中有一个对象是不完结的状态,那么它之后的Observable对象就不会有被取到的机会。
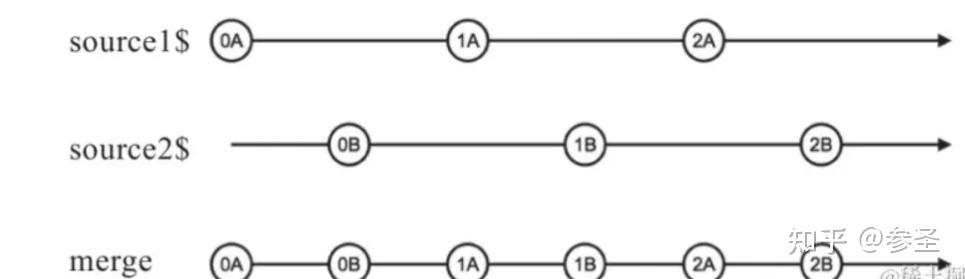
=> merge操作符 <= 作用: 一定性订阅上游所有的Observable对象,只要有数据传递下来,这个数据就会被传递给下游,也就是数据采取先到先出的原则,同时合并的时候原有数据不变
参数: merge(数据1, 数据2, 数据3, ... 可选数字参数)
场景一:合并异步数据流 import { merge, of, repeat, pipe } from "rxjs";
// 隔700ms重复一个A,重复的次数为5次
const source1$ = of("A").pipe(
repeat(
{ count: 5, delay: 700 }
));
// 隔800ms重复一个B,重复的次数为5次
const source2$ = of("B").pipe(
repeat(
{ count: 5, delay: 800 }
));
const merged$ = merge(source1$, source2$);
merged$.subscribe((res) => console.log(res));场景二: 同步限流 解释: 此时需要用到最后的参数 ,参数是一个数字,表示可以同时合并的个数
import { merge, of, repeat, pipe } from "rxjs";
// 隔700ms重复一个A,重复的次数为5次
const source1$ = of("A").pipe(
repeat(
{ count: 5, delay: 700 }
));
// 隔800ms重复一个B,重复的次数为5次
const source2$ = of("B").pipe(
repeat(
{ count: 5, delay: 800 }
));
// 隔900ms重复一个C,重复的次数为5次
const source3$ = of("C").pipe(
repeat(
{ count: 5, delay: 900 }
));
// 限定合并的个数为2
const merged$ = merge(source1$, source2$, source3$, 2);
merged$.subscribe((res) => console.log(res));场景三:合并多个事件 说明: 一个元素存在click 事件和touch 事件,对应网页和移动设备,假如其事件处理程序的逻辑一致,此时就可以分别使用fromEvent 获取单个事件流,之后用merge 合并成一个数据流,就可以集中管理了
// 可以像这样处理
const click$ = fromEvent(element, 'click');
const touchend$ = fromEvent(element, 'touchend');
merge(click$, touchend$).subscribe(处理函数);=> zip操作符 <= 作用: 将数据流里面的数据一一对应 并使用数组 组合起来
参数: zip(数据流1, 数据流2, 数据流3...)
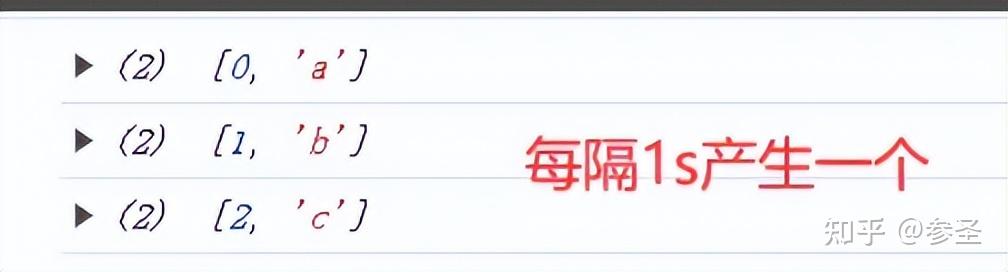
场景一: 一对一合并 import { interval, of, zip } from "rxjs";
// 一个异步数据流,产生的数据是无限的
const source1$ = interval(1000);
// 一个同步数据流,产生的数据流是有限
const source2$ = of("a", "b", "c");
// 将两个数据流合并
zip(source1$, source2$)
.subscribe(
(res) => console.log(res),
null,
() => console.log('complete')
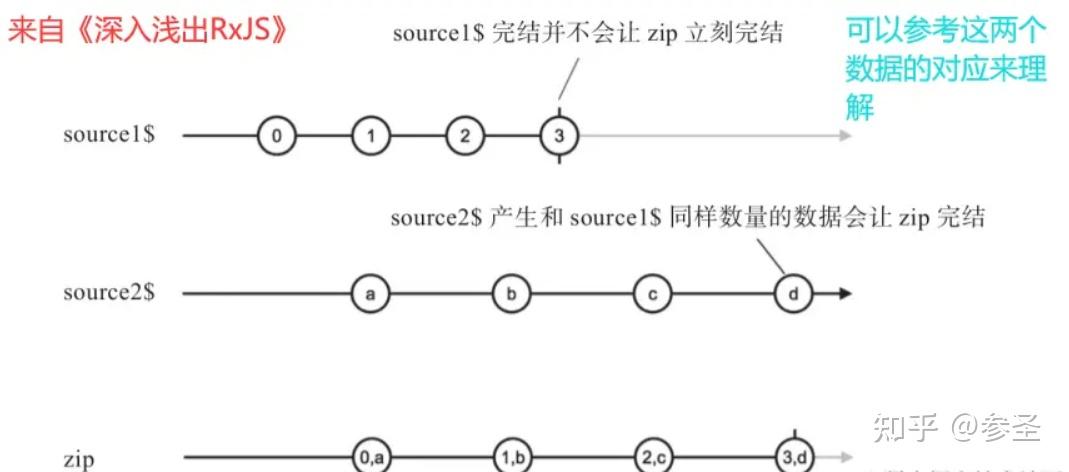
);注意: 这里数据的匹配是一一对应 的,所以数据少的那个Observable决定zip 产生数据的个数;然后在对应的时候需要双方都有数据 才能够对应,这也是为什么上面的打印会隔1s才打印。
问题: 数据积压 说明: 如果某个上游source1$吐出数据的速度很快,而另一个上游source2$吐出数据的速度很慢,那zip就不得不先存储source1$吐出的数据,因为RxJS的工作方式是“推”, Observable把数据推给下游之后就没有责任保存数据了。被source1$推送了数据之后,zip就有责任保存这些数据,等着和source2$未来吐出的数据配对。假如source2$迟迟不吐出数据,那么zip就会一直保存source1$没有配对的数据,然而这时候source1$可能会持续地产生数据,最后zip积压的数据就会越来越多,占用的内存也就越来越多。对于数据量比较小的Observable对象,这样的数据积压还可以忍受,但是对于超大量的数据流,使用zip就不得不考虑潜在的内存压力问题。
=> combineLatest操作符 <= 作用: 合并上游所有Observable一个最新的数据,也就是它返回值是一个数组
参数: combineLatest([数据1, 数据2, 数据3 ...], 处理函数)
场景一: 基本使用 import { combineLatest, timer } from "rxjs";
// 隔1s产生一个数字
const firstTimer = timer(1000, 1000);
// 隔2s产生一个数字
const secondTimer = timer(1000, 2000);
// 合并上面的数据流
const combinedTimers = combineLatest([firstTimer, secondTimer]);
combinedTimers.subscribe((value) => console.log(value));注意: 首先还是一一对应的关系,也就是如果一个数据源还没发射值出来,那么会等待它将值发射出来,如果值没有改变并且操作没有完结的话,发射的值将一直是这一个,所以只有所有的Observable对象完结,combineLatest才会给下游一个complete信号,表示不会有任何数据更新了
场景二: 合并同步数据流 const firstTimer = of("a", "b", "c");
const secondTimer = of(1, 2, 3);
const combinedTimers = combineLatest([firstTimer, secondTimer]);
combinedTimers.subscribe((value) => console.log(value));工作方式: combineLatest在工作的时候,会按照顺序依次订阅所有上游的Observable对象,只有所有上游Observable对象都已经吐出数据了,才会给下游传递所有上游“最新数据”组合的数据
解释: 由于of产生的同步数据流,在被订阅时就会吐出所有数据,最后一个吐出的数据是字符串c,这也就是最新的数据,然后订阅下一个对象,下一个对象会依次吐出数据,然后跟上一个对象的最新数据c结合,这就得到了上面看到的内容
场景三:定制下游数据 说明: 这里就需要啊使用处理函数了,这个函数的参数就是每一个数据源的最新值,其返回值就是下游所接受到的数据,如果没有返回值,则下游收到的数据为undefined
import { combineLatest, timer, of } from "rxjs";
const firstTimer = of("a", "b", "c");
const secondTimer = of(1, 2, 3);
const combinedTimers = combineLatest(
[firstTimer, secondTimer],
(res1, res2, res3) => {
// 上面只有两个数据源,所以参数只会前两个有值
console.log(res1, res2, res3);
}
);
combinedTimers.subscribe();
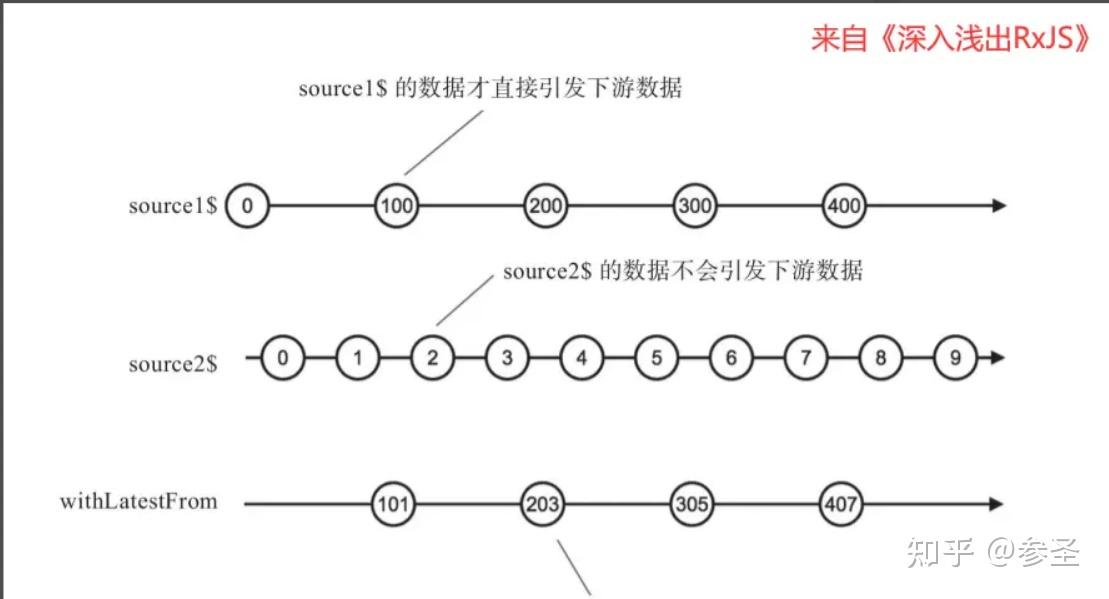
=> withLatestFrom操作符 <= 说明: 这个的作用于combineLatest是类似的,只不过下游推送数据只能由一个上游Observable对象驱动,也就是调用withLatestFrom的那个Observable对象起到主导数据产生节奏的作用,作为参数的Observable对象只能贡献数据,不能控制产生数据的时机
参数: 数据源1.withLatestFrom(数据源2)
import { withLatestFrom, timer, pipe, map } from "rxjs";
// 每隔两秒产生100、200、300这样的数字
const source1$ = timer(0, 2000)
.pipe(
map((x) => 100 * x)
);
// 每隔一秒产生0、1、2这样的数字
const source2$ = timer(500, 1000);
// 后面的处理函数将它们想加起来
const result$ = source1$
.pipe(
withLatestFrom(
source2$,
(a, b) => a + b
)
);
result$.subscribe(console.log);
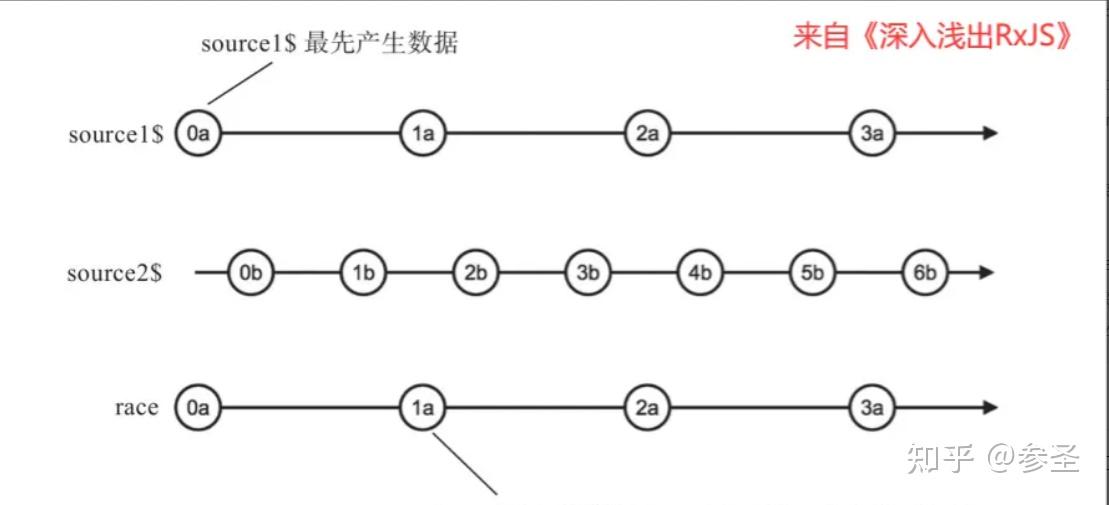
=> race操作符 <= 作用: 以Observable产生第一个数据的时间为准,只留下最快 的那一个,当然,使用的所有数据也是最快的那一个
参数: race(数据源1, 数据源2, 数据源3 ...)
import { timer, race, pipe, map } from "rxjs";
// 立即开始产生数据a
const source1$ = timer(0, 2000).pipe(map(() => "a"));
// 500ms后开始产生数据b
const source2$ = timer(500, 1000).pipe(map(() => "b"));
// 比赛
const winner$ = race(source1$, source2$);
winner$.subscribe(console.log);=> startWith操作符 <= 作用: 在让⼀个Observable对象在被订阅的时候,总是先同步 吐出指定的若⼲个数据
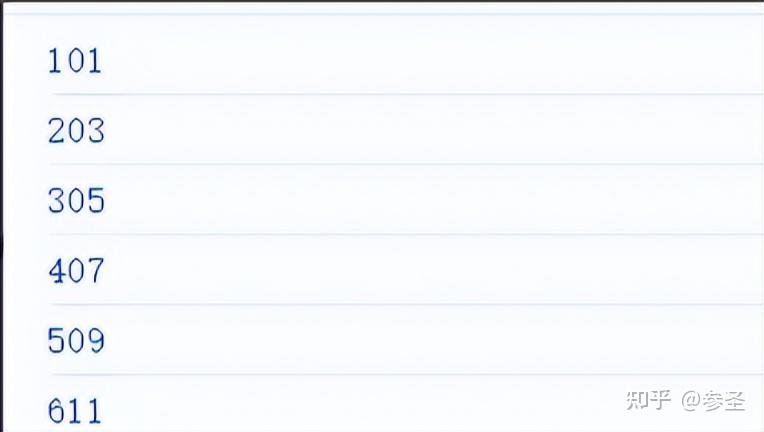
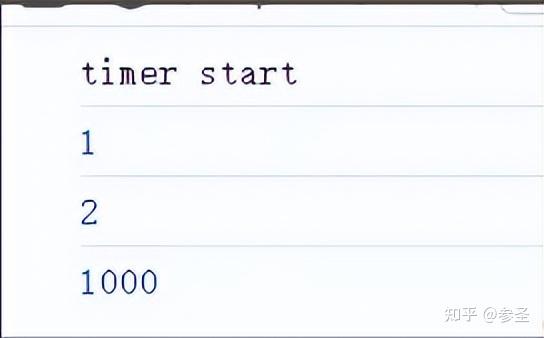
参数: 数据源.startWith(参数1, 参数2, 参数3 ...)
import { of, startWith } from "rxjs";
of(1000)
.pipe(startWith("timer start", 1, 2))
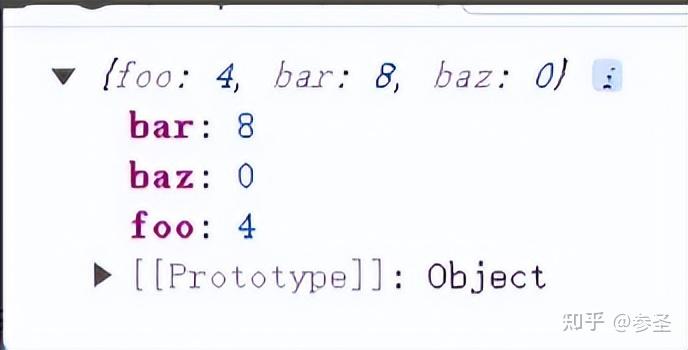
.subscribe((x) => console.log(x));=> forkJoin操作符 <= 作用: 等待所有参数Observable对象的最后⼀个 数据,将其合并成一个数组发射出去
参数: forkJoin(对象 / 数组)
import { forkJoin, of, timer } from "rxjs";
// 下面会在四秒后返回结果
forkJoin({
foo: of(1, 2, 3, 4),
bar: Promise.resolve(8),
baz: timer(4000),
}).subscribe((res) => console.log(res));(2)高阶Observable 说明: 简单理解就是一个Observable中存在Observable,它有一个特点就是高阶Observable完结不代表其里面的Observable完结
=> concatAll操作符 <= 说明: 这个操作符针对高阶Observable,也是依次订阅Observable内部的Observable取值结合,订阅的过程中如果上一个Observable没有完结就不会订阅下一个Observable对象。其他操作可以参照concat
参数: 没有参数
import { of, concatAll } from "rxjs";
const source = of(
of(1, 2, 3),
of(4, 5, 6),
of(7, 8, 9)
);
source.pipe(concatAll())
.subscribe(
(val) => console.log(val)
);=> mergeAll操作符 <= 说明: 针对高阶Observable,在合并的时候,依次订阅其内部的Observable对象,那个对象有数据传下来,这个数据就会传递给下游;它可以传递一个数字来限定合并的最大流的个数。其他操作可以参照merge
参数: mergeAll(数字)
import { of, mergeAll, repeat } from "rxjs";
// 这里A延迟复制的时间比B长,所以第二次打印的时候B在前面
const source = of(
of("A").pipe(
repeat({ count: 5, delay: 800 })
),
of("B").pipe(
repeat({ count: 5, delay: 700 })
)
);
source.pipe(mergeAll())
.subscribe(
(val) => console.log(val)
);=> zipAll操作符 <= 说明: 对高阶Observable使用的时候,将数据流里面的数据一一对应 并使用数组 组合起来。其它操作可以参考zip
参数: zipAll(处理函数)
import { of, zipAll } from "rxjs";
const source = of(of("A", "B", "C"), of(1, 2, 3), of("X", "Y", "Z"));
source
.pipe(
// 可以接收一个处理函数,每个参数对应返回值的每一项
zipAll((a, b, c) => {
// 这里将参数打印出来,如果没有返回值则下游将收不到值
console.log(a, b, c);
})
)
.subscribe();=> combineLatestAll操作符 <= 说明: 在处理高阶Observable的时候,将其内部Observable产生的最新数据一一对应并用数组的形式返回出来。其它操作可以参考combineLatest
参数: combineLatestAll(处理函数)
import { of, combineLatestAll } from "rxjs";
const source = of(of("A", "B", "C"), of(1, 2, 3), of("X", "Y", "Z"));
source
.pipe(
// 可以接收一个处理函数,每个参数对应返回值的每一项
combineLatestAll((a, b, c) => {
// 这里将参数打印出来,如果没有返回值则下游将收不到值
console.log(a, b, c);
})
)
.subscribe();五、辅助类操作符 (1)数学类操作符 说明: 这里介绍的操作符会遍历上游Observable对象中吐出的所有数据才给下游传递数据, 也就是说,它们只有在上游完结的时候,才给下游传递唯⼀数据。
=> count操作符 <= 作用: 用于统计上游Observable对象吐出的所有数据个数,所以上游的Observable需要完结
参数: count(过滤函数)
import { of, interval, count } from "rxjs";
// 可以完结
of(1000, 1)
.pipe(
// 此时过滤出数据为1的数量
count(
(val) => val === 1
)
)
.subscribe((res) => console.log(res));
// 无法完结
interval(1000)
.pipe(count())
.subscribe((res) => console.log(res));=> max和min操作符 <= 作用: 找出上游数据中的最大值 和最小值
参数: max(比较函数) / min(比较函数)
import { of, max } from "rxjs";
of(
{ age: 7, name: "Foo" },
{ age: 5, name: "Bar" },
{ age: 9, name: "Beer" }
).pipe(
// 返回值为正 => a > b
// 返回值为0 => a = b
// 返回值为负 => a < b
max((a, b) => a.age > b.age)
)
.subscribe(
(x) => console.log(x.name)
);注意: 如果Observable吐出的数据类型是复杂数据类型,⽐如⼀个对象,那必须指定⼀个⽐较这种复杂类型⼤⼩的⽅法,就像上面使用的那样
=> reduce操作符 <= 说明: 对上游的每个数据进行自定义计算,也就是对每一个元素都会调用一次这个函数
参数: reduce((累加的值, 当前元素的值) => {}, 初始值)
// 计算 1-100 的和
import { range, reduce } from "rxjs";
range(1, 100)
.pipe(
reduce(
(acc, current) => acc + current,
0
)
)
.subscribe(
(res) => console.log(res)
);2)条件操作符 说明: 根据上游Observable对象的某些条件产生一个新的 Observable对象
=> every操作符 <= 作用: 它接受一个判定函数作为参数,如果上游所有数据都能够通过这个函数,那么会返回一个包含true值的Observable,有一个通不过就返回一个包含false值的Observable,在吐出结果后every产生的Observable会立即完结;不要对不会完结的对象使用
参数: every(判定函数)
import { every, of } from "rxjs";
of(1, 100)
.pipe(
every(
// 这里判定是否所有值都大于10,显然1不行
(val) => val > 10
)
)
.subscribe((res) => console.log(res));=> find和findIndex操作符 <= 作用: 通过一个处理函数来在上游数据中查找满足条件的数据,find会吐出找到的上游的数据,findIndex会吐出满足判定条件的索引,如果找不到find会吐出undefined后完结,findIndex则会吐出-1后完结;不要对不会完结的对象使用
参数: find(处理函数) / findIndex(处理函数)
import { find, findIndex, of } from "rxjs";
of(1, 100)
.pipe(
find(
(val) => (val = 100)
)
)
.subscribe((res) => console.log(res));
of(1, 100)
.pipe(
findIndex(
(val) => (val = 100)
)
)
.subscribe((res) => console.log(res));=> isEmpty操作符 <= 作用: 检测上游Observable对象是不是空的,如果在完结之前没有 吐出数据,它就是空的,此时返回一个包含true 值的Observable,否则返回一个包含false 值的Observable
import { EMPTY, isEmpty, of } from "rxjs";
// 不是空的
of(1)
.pipe(isEmpty())
.subscribe((res) => console.log(res));
// 是空的
EMPTY.pipe(isEmpty())
.subscribe((res) => console.log(res));=> defaultIfEmpty操作符 <= 作用: 接受一个默认值,如果 检测上游的Observable是空的,则把这个默认值传递给下游,如果 不是空的就把上游的东西传递给下游;如果 不传但是上游检测还是空的,下游就会收到一个undefined 值
import { defaultIfEmpty, EMPTY, of } from "rxjs";
// 不是空值,不传参数
of(1)
.pipe(defaultIfEmpty())
.subscribe((res) => console.log(res));
// 不是空值,传参数
of(1)
.pipe(defaultIfEmpty("存在内容"))
.subscribe((res) => console.log(res));
// 是空值,不传参数
EMPTY.pipe(defaultIfEmpty())
.subscribe((res) => console.log(res));
// 是空值,传参数
EMPTY.pipe(defaultIfEmpty("存在内容"))
.subscribe((res) => console.log(res));六、过滤数据流 (1)过滤类操作符 说明: 对上游Observable中所有的数据使用判定函数进行操作,决定是否某些元素不能通过进入下游,如果对某个元素处理结果为true,表示能通过,否则就不能通过
=> filter操作符 <= 作用: 跟JavaScript中的filter使用起来是类似的,只不过这里针对的是Observable
参数: filter(过滤函数)
import { filter, interval } from "rxjs";
source$ = interval(1000)
.pipe(
// 过滤能被2整除的数据
filter(
(x) => x % 2 === 0
)
)
source$.subscribe((res) => console.log(res));注意: 当上游产⽣数据的时候,只要这个数据满⾜判定条件,就会立刻被同步传给 下游。
=> first操作符 <= 作用: 过滤出Observable中第一个满足条件的值,在没有找到的时候会抛出一个错误,如果不想这个错误传递给下游可以使用第二个默认值,它的作用是在没找到满足条件的值的时候将这个值传递出去。如果不传参数则将第一个数据返回出去,
参数: filter(过滤函数, 默认值)
import { first, of } from "rxjs";
// 找不到结果抛出错误,但是给默认值
of(1, 3)
.pipe(first((x) => x % 2 === 0, 2))
.subscribe((res) => console.log(res));
// 找到结果
of(1, 4, 3)
.pipe(first((x) => x % 2 === 0))
.subscribe((res) => console.log(res));
// 找不到结果抛出错误
of(1, 3)
.pipe(first((x) => x % 2 === 0))
.subscribe((res) => console.log(res));=> last操作符 <= 说明: 这个作用与first相反,它是找最后一个 满足条件的值,使用可以参考 first,这里需要注意 ,使用这个操作符的上游必须完结 ,否则操作符不知道哪一个是最后一个数据
参数: filter(过滤函数, 默认值)
import { last, interval } from "rxjs";
// 这个Observable不会完结,自然也不会拿到结果
interval(1000)
.pipe(last((x) => x % 2 === 0, 2))
.subscribe((res) => console.log(res));=> take操作符 <= 作用: 从上游的数据中拿指定个数 的数据,拿完之后就会完结,并将获取的数据返回
参数: take(需要的个数)
import { interval, of, take } from "rxjs";
// 数据不够拿,那就拿完为止
of("a", "b", "c")
.pipe(take(4))
.subscribe((res) => console.log(res));
// 获取指定个数的数据
interval(1000)
.pipe(take(4))
.subscribe((res) => console.log(res));注意: 上游每产生一个数据就会立即传给下游,也就是同步 操作的
=> takeLast操作符 <= 作用: 从后往前 获取指定个数 的数据,之后将数据一次性 返回出去之后完结
参数: takeLast(需要的个数)
import { interval, of, takeLast } from "rxjs";
// 数据不够拿,那就拿完为止
of("a", "b", "c")
.pipe(takeLast(4))
.subscribe((res) => console.log(res));
// 数据没有完结,获取不到数据
interval(1000)
.pipe(takeLast(4))
.subscribe((res) => console.log(res));注意: 如果上游的Observable对象不会完结的话,那么是拿不到数据的,因为不知道谁是最后一个数据
=> takeWhile操作符 <= 说明: takeWhile接受⼀个判定函数作为参数,这个判定函数有两个参数,分别代表上游的数据和对应的序号,takeWhile会吐出上游数据,直到判定函数返回false,只要遇到第一个判定函数返回false的情况, takeWhile产生的Observable就完结
参数: takeWhile(判定函数, 布尔值)
// 这里关注第二个参数
import { range, takeWhile } from "rxjs";
range(1, 10)
.pipe(
takeWhile(
(val) => val < 3, true
)
)
.subscribe((res) => console.log(res));
range(1, 10)
.pipe(
takeWhile(
(val) => val < 3, false
)
)
.subscribe((res) => console.log(res));注意: 第二个参数表示是否将第一次导致判定函数结果为false的那个值发射出去,默认是false,表示不发射,true则表示发射。
=> takeUntil操作符 <= 说明: 它接受一个Observable对象,在这个对象没有吐出数据之前,上游的数据会直接传递给下游,在参数对象吐出第一个数据时,上游的数据就不能传递给下游了。其次参数对象出现错误的时候,这个错误会传递给下游,此时上游数据也不能传递给下游了
参数: takeUntil(Observable对象)
// 假如使用interval创建数据,在第三秒的时候停止
import { interval, takeUntil, timer } from "rxjs";
interval(1000)
.pipe(
takeUntil(timer(3000))
)
.subscribe((res) => console.log(res));=> skip操作符 <= 作用: 跳过上游的前n个 值,然后从上游的第n+1个 值开始传递给下游,这个操作符不关心最后一个值是什么,所以 这个操作符的上游不管会不会完结下游都会有值。
参数: skip(跳过的个数)
import { interval, skip } from "rxjs";
// 跳过前两个值
interval(1000)
.pipe(skip(2))
.subscribe((res) => console.log(res));=> skipLast操作符 <= 作用: 可以理解成去除上游的最后n个 值,然后将剩下的值传递给下游;
参数: skipLast(跳过的n个值)
import { interval, skipLast, of } from "rxjs";
// 一个完结的对象
of("a", "b", "c")
.pipe(skipLast(2))
.subscribe((res) => console.log(res));
// 不会完结的对象
interval(1000)
.pipe(skipLast(2))
.subscribe((res) => console.log(res));注意: 上游没有完结下游依然可以收到数据
=> skipWhile操作符 <= 说明: 它接收一个函数作为参数,上游的每一个数据都会执行这个函数,只要有一个数据在函数中的返回值是false,那么这个数据之前的数据都会被过滤调用,剩下的数据会传递给下游。
参数: skipWhile(处理函数)
import { interval, skipWhile } from "rxjs";
interval(1000)
.pipe(skipWhile((val) => val % 2 === 0))
.subscribe((res) => console.log(res));=> skipUntil操作符 <= 作用: 用于在一个Observable中跳过一些值,直到另一个Observable发出了特定的信号或者达到某种状态。
参数: skipUntil(Observable对象)
import { interval, timer, skipUntil } from "rxjs";
// 创建一个每秒发出一个值的Observable
const source$ = interval(1000);
// 创建一个在5秒后发出第一个值的Observable
const trigger$ = timer(5000);
// 使用skipUntil操作符,跳过source$的值,直到trigger$发出第一个值
const example$ = source$.pipe(skipUntil(trigger$));
const subscription = example$.subscribe((val) => console.log(val));(2)有损回压控制 解释: 如果数据管道中某一个环节处理数据的速度跟不上数据涌现的速度,上游无法把数据推送给下游,就会在缓冲区中积压数据,这就相当于对上游施加了压力,这就是RxJS世界中的回压。
处理: 造成这种现象的原因是数据管道中某个环节数据涌⼊的速度超过了处理速度,那么,既然处理不过来,干脆就舍弃掉某些涌现的数据,这种方式称为有损回压控制
可选的调度器: => throttleTime操作符 <= 说明: 在一个时间范围内,上游传递给下游的数据只能传递一个;这里参数如果只传一个,其它值都会使用默认值;
参数: throttleTime(时间范围, 调度器, 可选参数对象)
import {
interval,
throttleTime,
asyncScheduler
} from "rxjs";
// 这里每隔1s产生一个数字
interval(1000)
.pipe(
throttleTime(
2000,
asyncScheduler,
// trailing为true时产生的结果是:2、4、6...
// leading为true时产生的结果是:3、6、9...
{ leading: false, trailing: true }
)
)
.subscribe((res) => console.log(res));=> debounceTime操作符 <= 说明: 在一个时间范围内,一直有数据产生一直不会将数据传递给下游,只有在这个时间外产生的第一个数据才会传递给下游;所以产生数据的间隔需要大于这个时间范围才可以
参数: throttleTime(时间范围, 调度器)
import { interval, debounceTime, asyncScheduler } from "rxjs";
// 这里的值如果比2000还小那么就不会有数据打印出来
interval(4000)
.pipe(debounceTime(2000, asyncScheduler))
.subscribe((res) => console.log(res));=> throttle和debounce操作符 <= 作用: 这两个都是使用Observable中的数据来控制流量,区别 在于时机不同而已
参数: throttle(处理函数, 可选参数对象)
参数: debounce(处理函数)
// 这里以throttle为例
import { interval, timer, throttle } from "rxjs";
const source$ = interval(1000);
// 处理函数的参数只能拿到上游的数据
const durationSelector = (value) => {
console.log(`# call durationSelector with ${value}`);
return timer(2000);
};
const result$ = source$.pipe(throttle(durationSelector));
result$.subscribe(console.log);理解: 当source$产生第一个数据0的时候,throttle就和throttleTime一样,毫不 犹豫地把这个数据0传给了下游,在此之前会将这个数据0作为参数调用 durationSelector,然后订阅durationSelector返回的Observable对象,在这个 Observable对象产生第一个对象之前,所有上游传过来的数据都会被丢弃,于是,source$产生的数据1就被丢弃了,因为durationSelector返回的 Observable对象被订阅之后2000毫秒才会产生数据。 这个过程,相当于throttle每往下游传递一个数据,都关上了上下游之间闸门,只有当durationSelector产生数据的时候才打开这个闸门。到了2000毫秒的时刻,durationSelector第二次被调用产生的Observable对象终于产生了多个数据,闸门被打开,source$产生的第三个数据2正好赶上,被 传递给了下游,同时关上闸门,这时候throttle会立刻退订上一次 durationSelector返回的Observable对象,重新将数据2作为参数调用 durationSelector来获得一个新的Observable对象,这个新的Observable对象产生数据的时候,闸门才会再次打开。可见,durationSelector产生Observable对象只有第一个产生的数据会有作用,而且这个数据的产生时机是关键,至于这个数据是个什么值不重要。
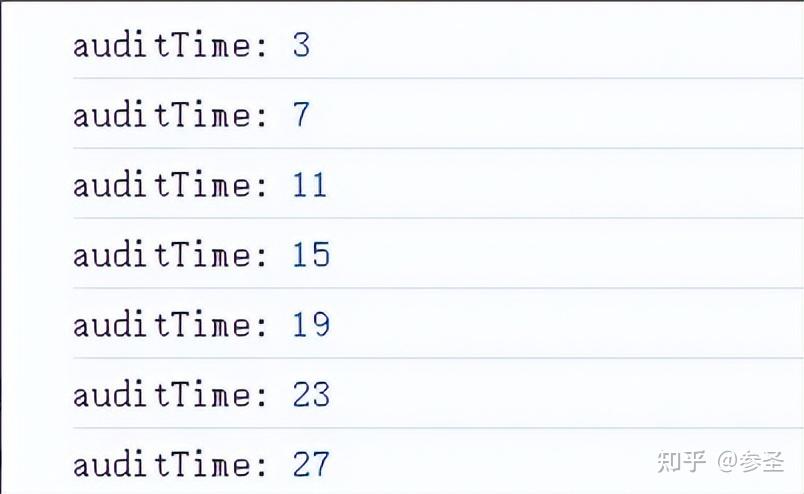
=> auditTime和audit操作符 <= 说明: 这两个都是在一个时间内,将最后一个产生的值发射出去,其余的值会被忽略掉。它们之间的区别是一个使用时间范围管理,一个使用函数管理
参数: auditTime(时间范围, 可选参数对象)
参数: audit(处理函数)
import { interval, auditTime } from "rxjs";
interval(1000)
.pipe(auditTime(3000))
.subscribe(
(val) => console.log("auditTime:", val)
);
// 第一个3s:0、1、2、3 --> 三秒末也是四秒初发出值3
// 第二个3s:4、5、6、7 --> 六秒末也是七秒初发出值7
// ...理解: 上面的时间写3s,所以在第一个3s内产生了值0、1、2,在第3s结束的时候,产生了值3,根据定义,所以第一个3s发出的值是3,在物理上,第n秒结束的时候,也就是第n+1秒开始的时候,所以下一个3s是从第四秒开始,然后这个时间内产生4、5、6,第7s结束的时候,产生值7,将其传递给下游...后面的值都是这样产生的,也就是它发出一个值传递到下游之后,它会等待下一个值到达,才会开始其计时
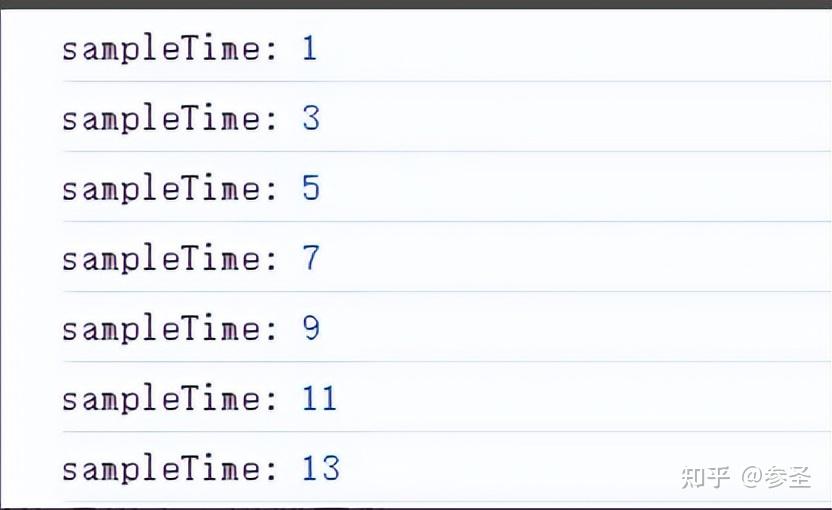
=> sampleTime和sample操作符 <= 说明: sampleTime的作用是搜寻一个时间范围内的最后一个数据,将其传递给下游,如果这个时间范围里面没有值则不会传值到下游,然后继续下一个时间范围的搜寻; 而sample有点不同,它的参数接收一个Observable对象来控制Observable,这个参数被称为notifier,当notifier产生一个数据的时候, sample就从上游拿最后一个产生的数据传给下游。
参数: sampleTime(时间范围, 调度器)
参数: sample(observable对象)
interval(1000)
.pipe(sampleTime(2000))
.subscribe((res) => console.log("sampleTime:", res));理解: 上面数据是每隔1s产生一个,然后我搜寻时间范围是2s,第一个2s,产生值0、1,将1传递出去,继续第二个2s的搜寻,产生值2、3,将3传递出去...以此类推
(3)去重 => distinct操作符 <= 作用: 上游同样的数据只有第一次产生时会传给下游,其余的都被舍弃掉了,判断是否相等使用的是===
参数: distinct(一个函数来定制需要对比什么属性, 一个Observable对象用于清空数据)
场景一: 基本使用 import { distinct, of } from "rxjs";
of(1, 3, 2, 5, 7, 1, 2)
.pipe(distinct())
.subscribe((res) => console.log(res));
场景二: 对对象使用
import { distinct, of } from "rxjs";
of(
{ name: "RxJS", version: "v4" },
{ name: "React", version: "v15" },
{ name: "React", version: "v16" },
{ name: "RxJS", version: "v5" }
)
// 这里规定数据中的name字段相同就算相同数据
.pipe(distinct((x) => x.name))
.subscribe((res) => console.log(res));第二个参数: distinct在运作的时候自己会先创建一个集合,里面存放上游的不同数据,每次上游传递一个数据出来就对比集合中是否有元素跟它相等,相等就舍弃,如果上游数据无限多切都是不同的,那么这个集合就会有无限的数据在里面,这就存在数据压力,为了解决这个问题,可以使用第二个可选参数,当这个Observable对象产生数据的时候,这个集合中的数据就会被清空。
=> distinctUntilChanged操作符 <= 作用: 将上游中的连续数据过滤掉
参数: distinctUntilChanged(比较函数)
import { distinctUntilChanged, of } from "rxjs";
of(
{ name: "RxJS", version: "v4" },
{ name: "React", version: "v15" },
{ name: "React", version: "v16" },
{ name: "RxJS", version: "v5" }
)
// a表示上一个值,b表示当前值
.pipe(distinctUntilChanged((a, b) => a.name === b.name))
.subscribe((res) => console.log(res));注意: 比较函数需要返回布尔值来确定由哪些属性决定数据相等
(4)其它 => ignoreElements操作符 <= 作用: 忽略上游所有元素,只关心complete和error事件
参数: 没有参数
import { ignoreElements, of } from "rxjs";
of(1, 2, 3)
.pipe(ignoreElements())
.subscribe((res) => console.log(res));=> elementAt操作符 <= 说明: 把上游数据当数组,只获取指定下标的那⼀个数据,如果找不到,则抛出一个错误事件,如果不想出现错误,可以使用第二个参数,在找不到的时候,会将第二个参数做为默认值传递给下游
参数: elementAt(下标, 默认值)
import { elementAt, of } from "rxjs";
of(1, 2, 3)
.pipe(elementAt(3, "使用默认值作为数据传递给下游"))
.subscribe((res) => console.log(res));=> single操作符 <= 作用: 检查上游是否只有一个满足对应条件的数据,如果答案为是,就向下游传递这个数据;如果答案为否,就向下游传递一个异常
参数: single(过滤函数)
import { of, single } from "rxjs";
of(1, 2, 3)
.pipe(single((x) => x % 2 === 0))
.subscribe((res) => console.log(res));七、转化数据流 (1)映射数据 理解: 映射数据是最简单的转化形式。假如上游的数据是A、B、C、D的序列,那么可以认为经过转化类操作符之后,就会变成f(A)、f(B)、f(C)、f(D)的序列,其中f是一个函数,作用于上游数据之后,产生的就是传给下游新的数据
=> map操作符 <= 说明: 它接受一个函数作为参数,这个函数通常称为project,指定了数据映射的逻辑 ,每当上游推下来一个数据,map就把这个数据作为参数传给map的参数函数,然后再把函数执行的返回值 推给下游
参数: map(处理函数)
import { of, map } from "rxjs";
of(1, 2, 3)
.pipe(
map((item, index) => {
// 处理函数的item表示当前值,index表示当前值得索引
console.log(item, index);
})
)
.subscribe();2)无损回压控制 说明: 把上游在一段时间内产生的数据放到一个数据集合中,当时机合适时,把缓存的数据汇聚到一个数组或者Observable对象传给下游,这就是无损回压控制
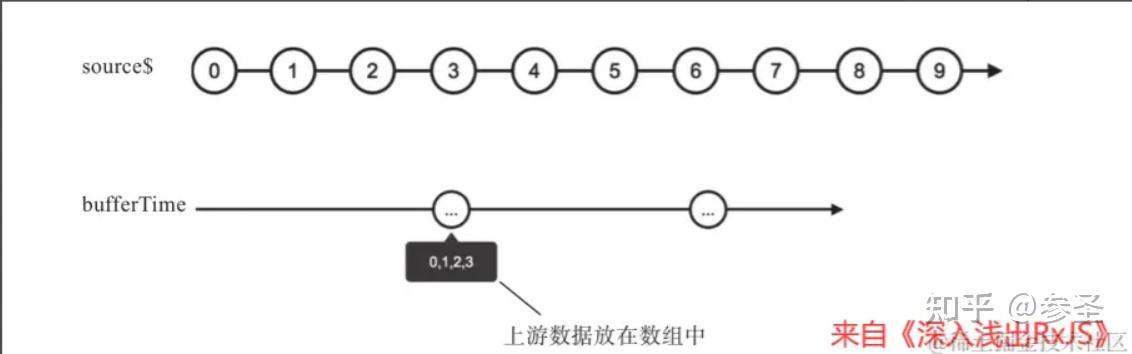
=> windowTime和bufferTime操作符 <= 作用: 用一个参数来指定产生缓冲窗口的时间间隔,以此缓存上游的数据
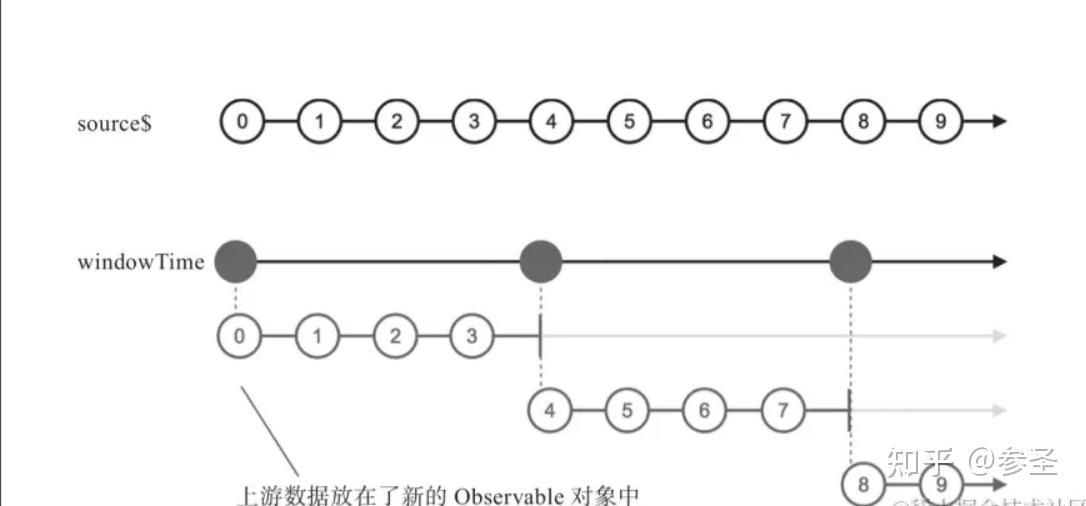
参数: windowTime(划分区块间隔, 内部区块开始间隔, 最多缓存数据个数)
参数: bufferTime(划分区块间隔, 内部区块开始间隔, 最多缓存数据个数)
场景一: 基本使用 import { timer, windowTime } from "rxjs";
const source$ = timer(0, 1000);
const result$ = source$.pipe(windowTime(4000));理解: windowTime的参数是4000,也就会把时间划分为连续的4000毫秒长度区块,在每个时间区块中,上游传下来的数据不会直接送给下游,而是在该时间区块的开始就新创建一个Observable对象推送给下游,然后在这个时间区块内上游产生的数据放到这个新创建的Observable对象中。在每个4000毫秒的时间区间内,上游的每个数据都被传送给对应时间区间的内部Observable对象中,当4000毫秒时间一到,这个区间的内部Observable对象就会完结,将结果打印出来会发现控制台每隔1000毫秒打印一个数字出来,因此windowTime把上游数据传递出去是不需要延迟的
import { bufferTime, timer } from "rxjs";
const source$ = timer(0, 1000);
const result$ = source$
.pipe(bufferTime(4000))
.subscribe((res) => console.log(res));理解: bufferTime产⽣的是普通的Observable对象,其中的数据是数组形式, bufferTime会把时间区块内的数据缓存,在时间区块结束的时候把所有缓存的数据放在一个数组再传给下游,在控制台你会看见每隔4秒打印一个数组,因此bufferTime把上游数据传递出去是需要延迟的
场景二: 第二个参数 作用: 指定每个时间区块开始的时间间隔。
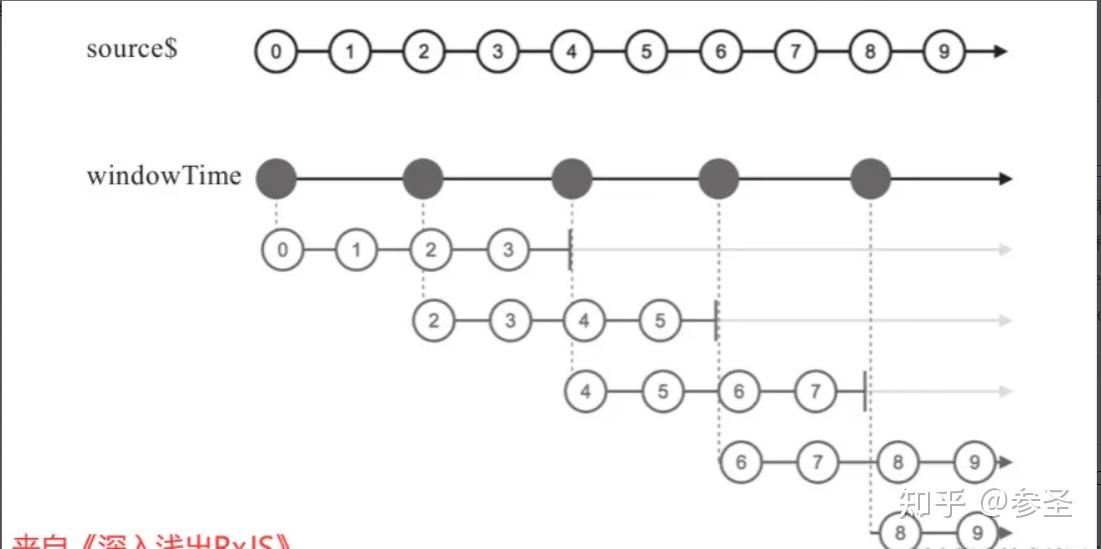
import { timer, windowTime } from "rxjs";
const source$ = timer(0, 1000);
source$.pipe(windowTime(4000, 2000)).subscribe();理解: windowTime使用第二个参数200之后,产生内部Observable的频率更高了,每200毫秒就会产生一个内部Observable对象, 而且各内部Observable对象中的数据会重复,例如数据2和3就同时出现在第一个和第二个内部Observable对象中
import { bufferTime, timer } from "rxjs";
const source$ = timer(0, 1000);
source$
.pipe(bufferTime(4000, 2000, 2))
.subscribe(console.log);理解: 对于bufferTime,因为需要缓存上游数据,不管参数设定的数据区间有多短,都无法预期在这段时间内上游会产生多少数据,如果上游在短时间内爆发出很多数据,那就会给bufferTime很大的内存压力,为了防止出现这种情况可以使用第三个可选参数来指定每个时间区间内缓存的最多数据个数。
注意: 如果第一个参数比第二个参数大,那么就有可能出现数据重复,如果第二个参数比第一个参数大,那么就有可能出现上游数据的丢失。之所以说“有可能”,是因为丢失或者重叠的时间区块中可能上游没有产生数据,所以也就不会引起上游数据的丢失和重复。从这个意义上说来,windowTime和bufferTime如果用上了第二个参数,也未必是“止损”的回压控制。
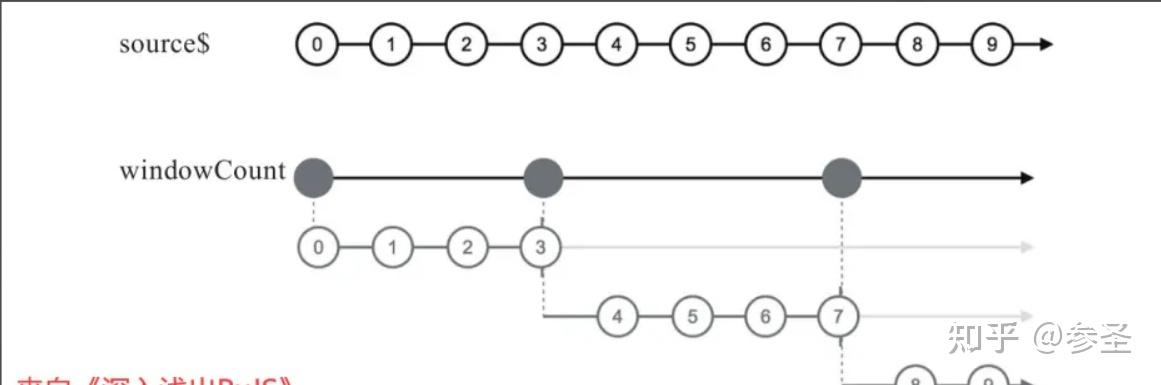
=> windowCount和bufferCount操作符 <= 作用: 根据数据个数来决定内部的一个Observabe需要保存多少数据。
参数: windowCount(时间区间长度, 隔几个数据重新开一个区间)
import { timer, windowCount } from "rxjs";
const source$ = timer(0, 1000);
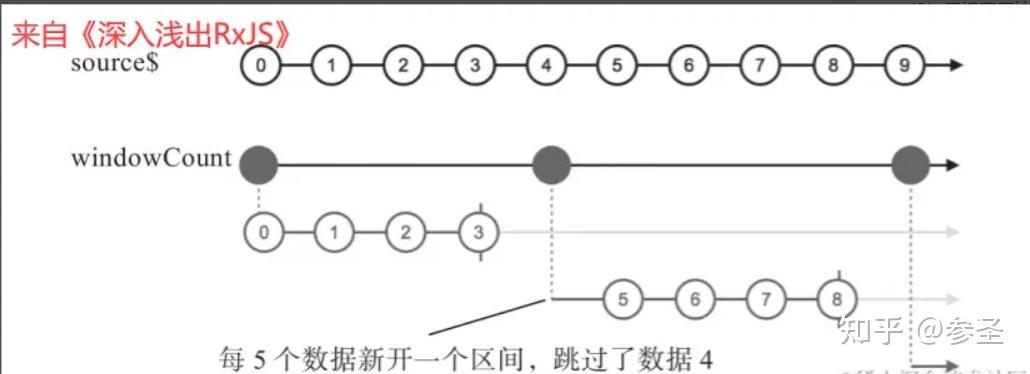
source$.pipe(windowCount(4)).subscribe(console.log);import { timer, windowCount } from "rxjs";
const source$ = timer(0, 1000);
source$.pipe(windowCount(4, 5)).subscribe(console.log);理解: windowCount还支持可选的第二个参数,如果不使用第二个参数,那么所有的时间区间没有重叠部分;如果使用了第二个参数,那么第二个参数依然是时间区间的长度,但是每间隔第二个参数毫秒数,就会新开一个时间区间
说明: 对于bufferCount,和windowCount一样,区别只是传给下游的是缓存数据组成的数组
=> windowWhen和bufferWhen操作符 <= 说明: 它们接受一个函数作为参数,这个函数返回一个Observable对象,用于控制上游的数据分割,每当返回的Observable对象产生数据或者完结时,windowWhen就认为是一个缓冲区块的结束,重新开启一个缓冲窗口。bufferWhen跟这个是类似的
参数: windowWhen(处理函数)
import { timer, windowWhen } from "rxjs";
const source$ = timer(0, 100);
const closingSelector = () => {
return timer(400);
};
// 被订阅的时候windowWhen就开始⼯作,⾸先开启⼀个缓冲
// 窗口,然后⽴刻调⽤closingSelector获得⼀个Observable对象,
// 在这个Observable对象输出数据的时候,当前的缓冲窗⼜就关闭,
// 同时开启⼀个新的缓冲窗口,然后再次调⽤closingSelector
// 获得⼀个Observable对象
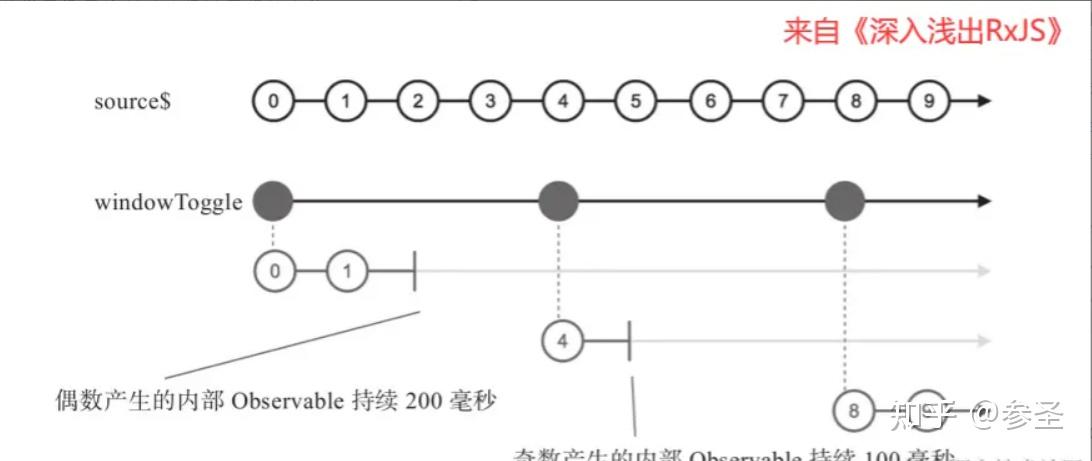
source$.pipe(windowWhen(closingSelector));=> windowToggle和bufferToggle操作符 <= 说明: 利⽤Observable来控制缓冲窗口的开和关。它需要两个参数,第一个参数是一个Observable对象,当产生一个数据,代表一个缓冲窗口的开始;同时,第二个参数是一个函数,它也会被调用,用来获得缓冲窗口结束的通知;其次函数的参数是第一个参数产生的数据,这样就可以由前一个参数控制缓冲窗口的开始时机,函数控制其关闭时机,从而控制产生高阶Observable的节奏;同理bufferToggle也是类似的
import { timer, windowToggle } from "rxjs";
const source$ = timer(0, 100);
const openings$ = timer(0, 400);
const closingSelector = (value) => {
return value % 2 === 0 ? timer(200) : timer(100);
};
// opening$每400毫秒产⽣⼀个数据,所以每400毫秒就会有⼀个
// 缓冲区间开始。每当opening$产⽣⼀个数据时,closingSelector
// 就会被调⽤返回控制对应缓冲区间结束的Observable对象,
// 如果参数为偶数,就会延时200毫秒产⽣⼀个数据,否则就延时100
// 毫秒产⽣⼀个数据
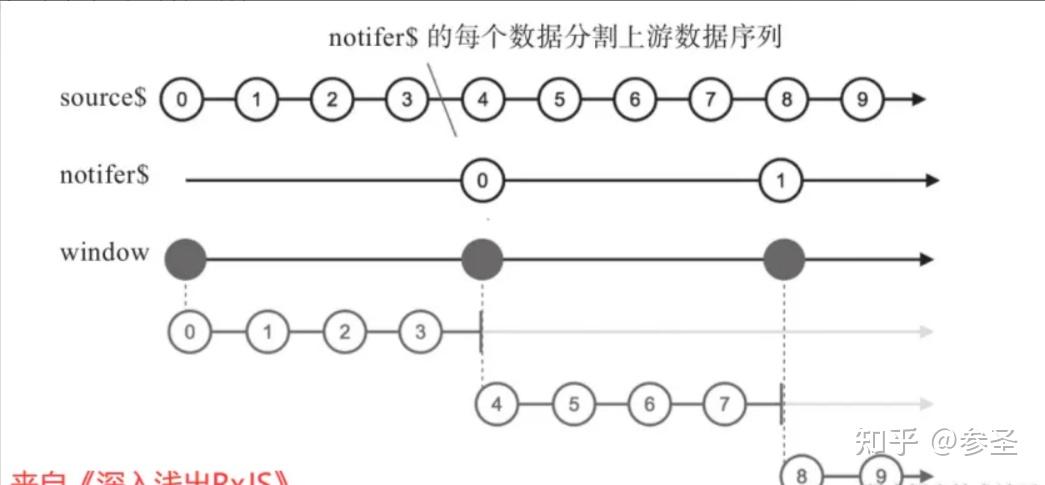
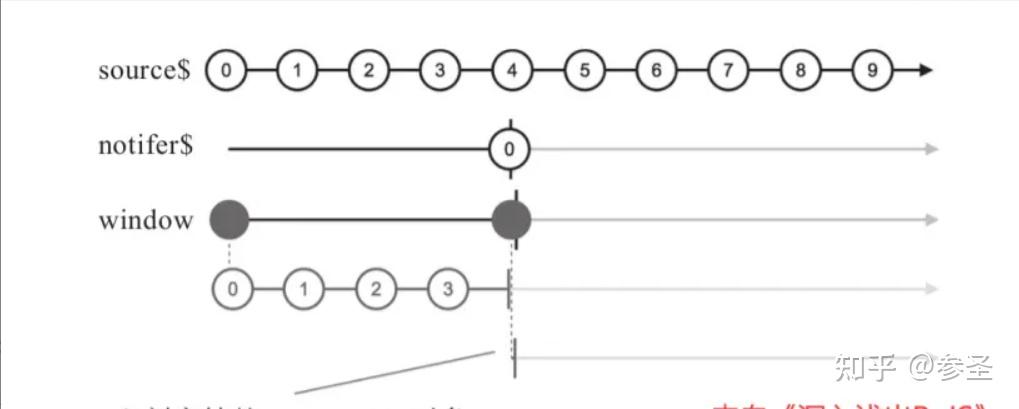
source$.pipe(windowToggle(openings$, closingSelector));=> window和buffer操作符 <= 说明: 保持一个Observable类型的参数,称为notifier$,每当notifer$产生一个数据,既是前一个缓存窗口的结束,也是后一个缓存窗口的开始;如果这个Observable完结了,那么window产生的一阶Observable对象也会完结,buffer也是类似的
参数: window(一个Observable对象)
import { timer, window } from "rxjs";
const source$ = timer(0, 100);
// 一个不会完结的Observable
const notifer$ = timer(400, 400);
source$.pipe(window(notifer$));import { timer, window } from "rxjs";
const source$ = timer(0, 100);
// 一个会完结的Observable
const notifer$ = timer(400);
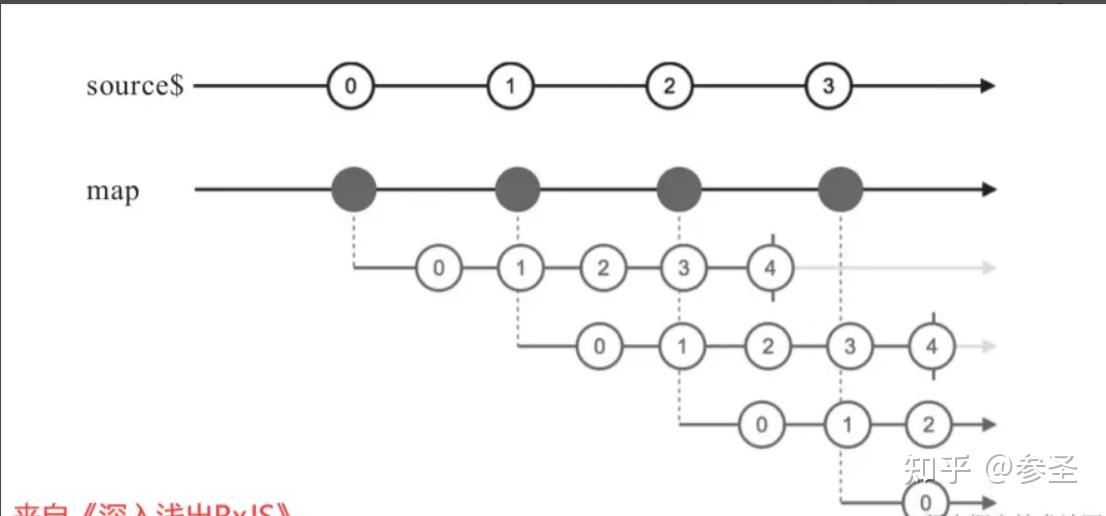
source$.pipe(window(notifer$));(3)高阶map 说明: 传统map与高阶map的区别在于其函数参数的返回值,前者是将一个数据映射成另一个数据 ,而后者是将一个数据转变成一个Observable
import { interval, map } from "rxjs";
const source$ = interval(200);
// 这里每个数据都会转换成一个包含数字0、1、2、3、4的
// Observable对象
source$.pipe(
map(
() => interval(100).take(5)
)
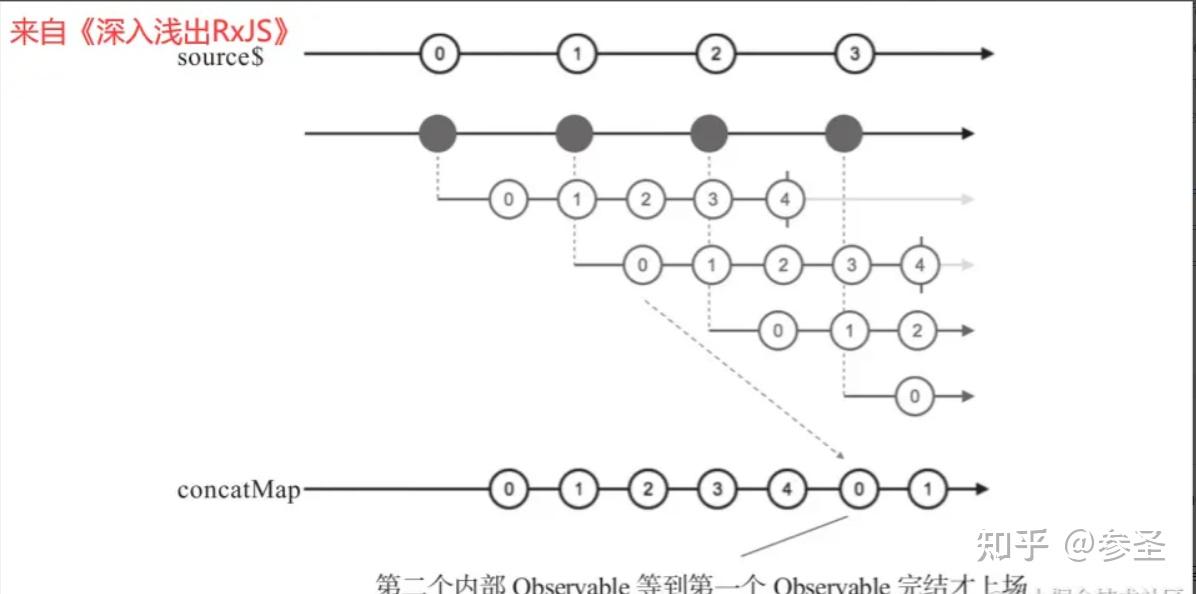
);=> concatMap操作符 <= 说明: 可以理解成concatMap = map + concatAll
import { interval, concatMap } from "rxjs";
const source$ = interval(200);
source$.pipe(
concatMap(
() => interval(100).take(5)
)
);理解: 第一个内部Observable对象中的数据被完整传递给了 concatMap的下游,但是,第一个产生的内部Observable对象没有那么快处理,只有到第一个内部Observable对象完结之后,concatMap才会去订阅第二个内部Observable,这样就导致第二个内部Observable对象中的数据排在了后面,绝不会和第一个内部Observable对象中的数据交叉。
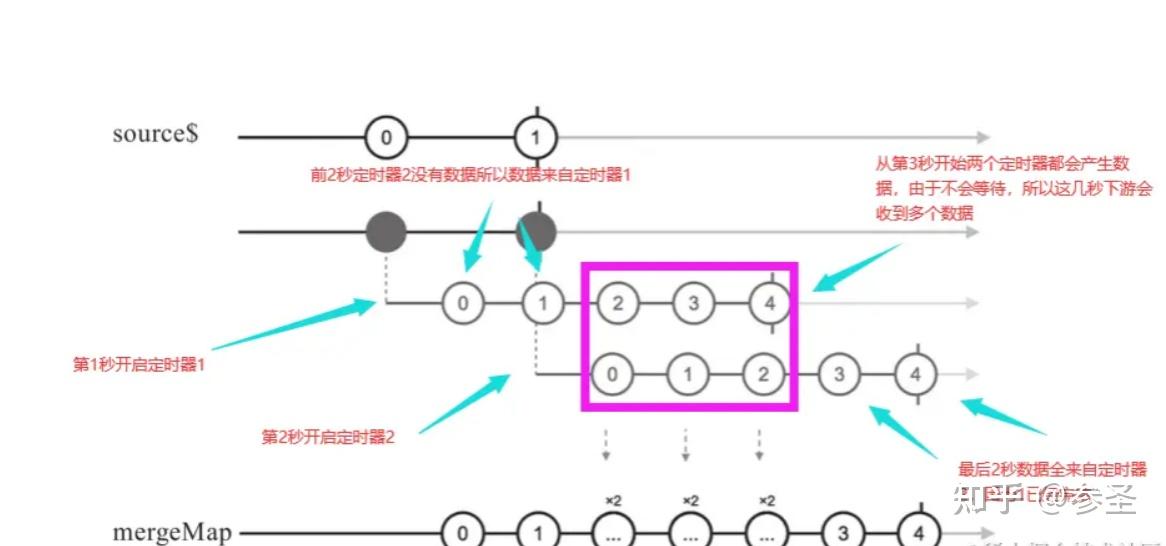
=> mergeMap操作符 <= 说明: 可以理解成mergeMap = map + mergeAll
注意: 一旦内部Observable发出一个值,它就会立即将该值传递给下游观察者,而不管其他内部Observable是否已经发出或者完成了
import { interval, mergeMap, take } from "rxjs";
const source$ = interval(200).take(2);
source$.pipe(
mergeMap(
() => interval(100).take(5)
)
);=> switchMap操作符 <= 说明: 可以理解成switchMap = map + switchAll
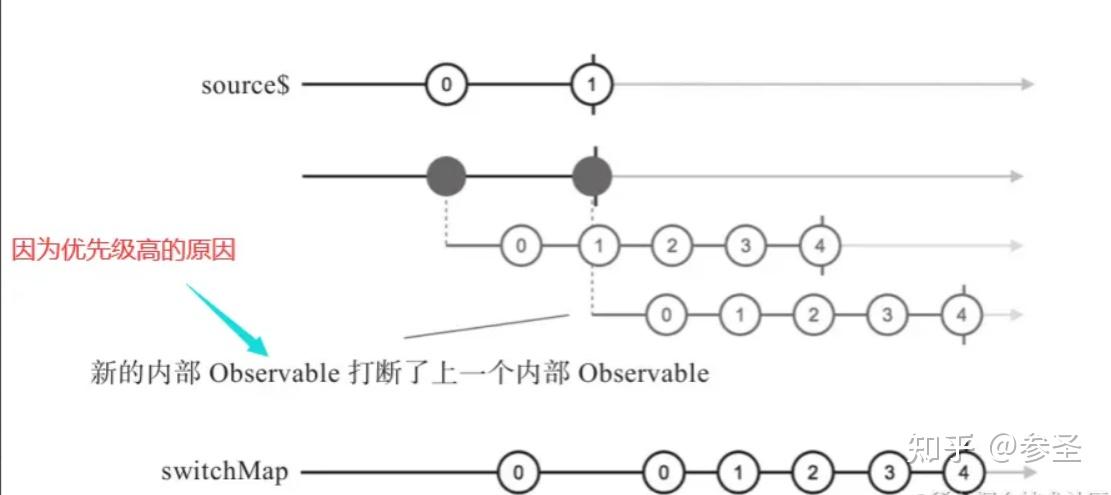
注意: 后产生的内部Observable对象优先级总是更高,只要有新的内部Observable对象产生,就立刻退订之前的内部 Observable对象,改为从最新的内部Observable对象拿数据
import { interval, switchMap, take } from "rxjs";
const source$ = interval(200).take(2);
source$.pipe(
switchMap(
() => interval(100).take(5)
)
);4)分组 => groupBy操作符 <= 参数: groupBy(一个处理函数,用于得到数据的key值)
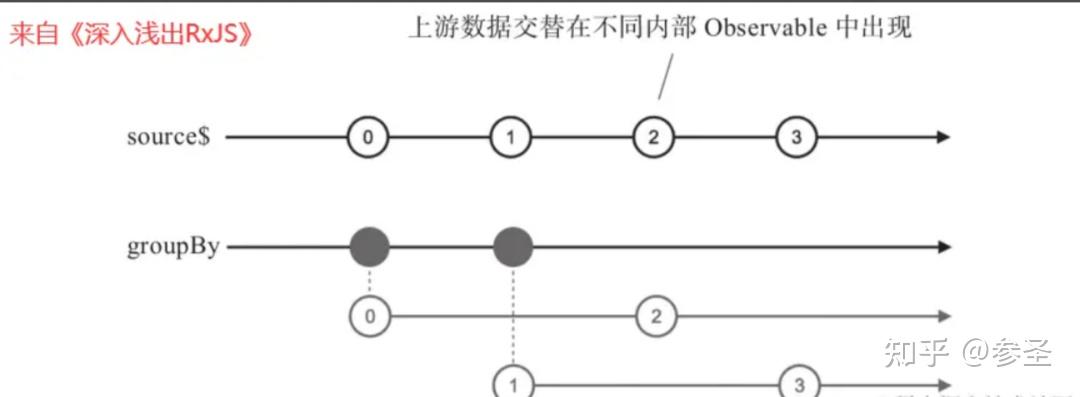
机制: 对于上游推送下来的任何数据,检查这个数据的key值,如果这个key值是第一次出现,就产生一个新的内部Observable对象,同时这个数据就是内部Observable对象的第一个数据;如果key值已经出现过,就直接把这个数据塞给对应的内部Observable对象
import { groupBy, interval } from "rxjs";
const source$ = interval(200);
source$.pipe(groupBy((val) => val % 2));理解: groupBy的函数参数取的是参数除以2的余数,所以会产生两个key值:0和1。从弹珠图中可以看到,0和2属于第一个内部 Observable对象,第一个内部Observable对象收纳所有key值为0的数据,1 和3属于第二个内部Observable对象,因为它们对应的key值为1
=> partition操作符 <= 说明: partition接受一个判定函数作为参数,对上游的每个数据进行判定,满足条件的放一个Observable对象,不满足条件的放到另一个Observable对象,就这样来分组,它返回的是一个数组,包含两个元素,第一个元素是容纳满组判定条件的Observable对象,第二个元素当然是不满足判定条件的Observable对象。
参数: partition(数据源, 判定函数)
import { partition, timer } from "rxjs";
const source$ = timer(0, 100);
// 解构赋值
const [even$, odd$] = partition(source$, (x) => x % 2 === 0);
even$.subscribe((value) => console.log("even:", value));
odd$.subscribe((value) => console.log("odd:", value));注意: 使用 partition一般也不会在后面直接使用链式调用,需要把结果以变量存储,然后分别处理结果中的两个Observable对象
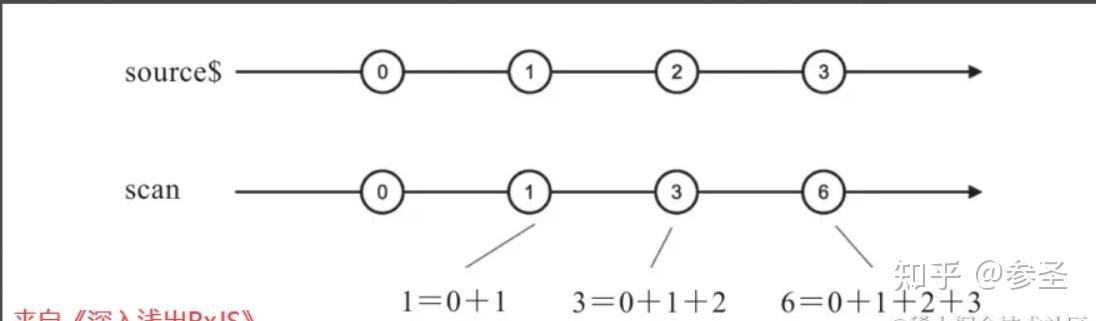
(5)累计数据 => scan操作符 <= 说明: 与reduce操作符类似,它也有一个求和函数参数和一个可选的seed种子参数作为求和初始值。scan和reduce的区别在于scan对上游每一个数据都会产生一个求和结果,reduce是对上游所有数据进行求和,reduce最多只给下游传递一个数据,如果上游数据永不完结,那reduce也永远不会产生数据,scan完全可以处理一个永不完结的上游Observable对象
参数: scan(求和函数, 初始值)
import { interval, scan } from "rxjs";
const source$ = interval(1000);
source$
.pipe(
// sum:上一次求和后的值
// current:当前需要进行求和的值
scan((sum, current) => {
console.log(sum, current);
return sum + current;
})
)
.subscribe();理解: scan的规约函数参数把之前求和的值加上当前数据作为求和结果,每一次上游产生数据的时候,这个求和函数都会被调用,结果会传给下游,同时结果也会由scan保存,作为下一次调用规约函数时的sum参数
=> mergeScan操作符 <= 说明: 它在使用的时候跟scan是类似的,不过它的返回值是一个Observable对象
机制: 每当上游推送一个数据下来,mergeScan就调用一次求和函数,并且订阅返回的Observable对象,之后,这个Observable对象会使用类似merge的方式与下游合并,此时mergeScan会记住传给下游的最后一个数据,当上游再次推送数据下来的时候,就把最后一次传递给下游的数据作为求和函数的sum参数
注意: 如果mergeScan返回一个复杂或者不会完结的Observable对象,可能会导致上游数据和返回的Observable对象会交叉传递数据给下游,这样那个值是最后一次传递给下游的会很难确定,因此在使用的时候返回的Observable里面包含的值尽量简单
八、错误处理 说明: 错误异常和数据一样,会沿着数据流管道从上游向下游流动,流过所有的过滤类或者转化类操作符,最后会触发Observer的error方法,不过也不是所有错误都交给Observer处理,不然它需要处理的东西就太多了,此时就需要在数据管道中处理掉,这里处理异常有两类方法:恢复和重试。在实际应用中,重试和恢复往往配合使用,因为重试往往是有次数限制的,不能无限重试,如果尝试了次数上限之后得到的依然是错误异常, 还是要用“恢复”的方法获得默认值继续运算。
恢复:就是本来虽然产生了错误异常,但是依然让运算继续下去。最常见的场景就是在获取某个数据的过程中发生了错误,这时候虽然没有获得正确数据,但是用一个默认值当做返回的结果,让运算继续。 重试:就是当发现错误异常的时候,认为这个错误只是临时的,重新尝试之前发生错误的操作,寄希望于重试之后能够获得正常的结果,其本质是在订阅上游的同时,退订上一次订阅的内容 => catchError操作符 <= 作用: 会在管道中捕获上游传递过来的错误
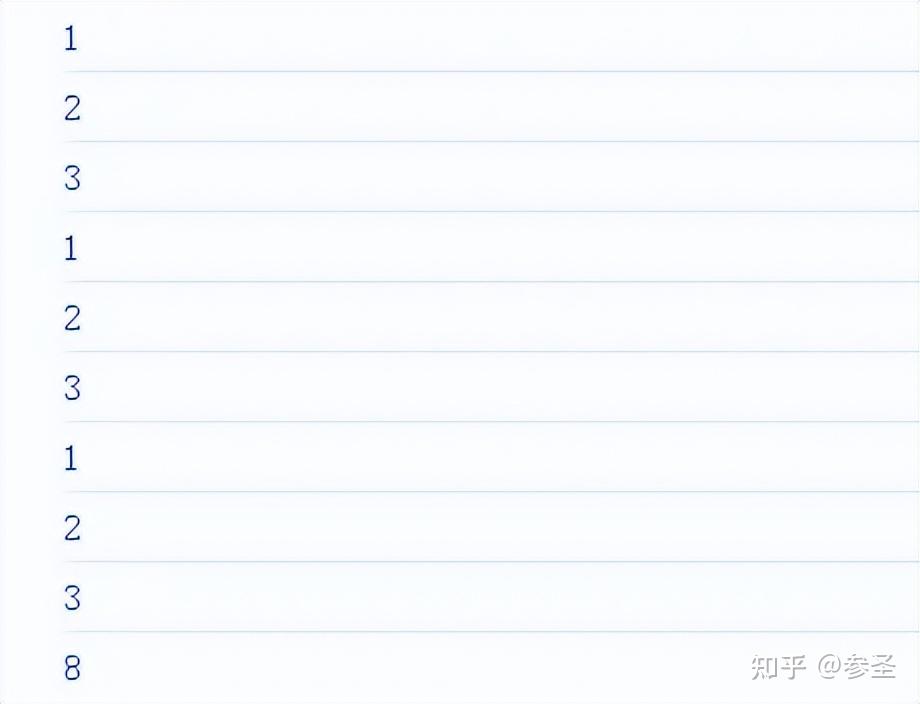
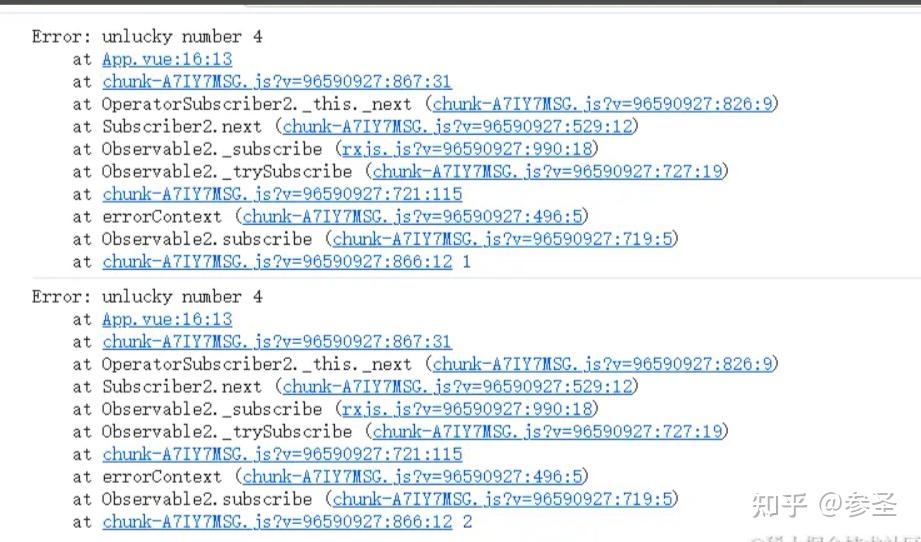
参数: catchError(异常函数)
import { range, map, catchError, of } from "rxjs";
// 产生数据1、2、3、4、5
const source$ = range(1, 5);
// 遍历数据发现在4这个位置会抛出一个错误
const error$ = source$.pipe(
map((value) => {
if (value === 4) {
throw new Error("unlucky number 4");
}
return value;
})
);
// 此时错误会被catchError的处理函数所接收
const catch$ = error$
.pipe(
// err:被捕获的错误
// caught$:上游紧邻的那个Observable对象,此处就是指error$了
catchError((err, caught$) => {
// 函数的返回值是一个Observable对象,用来替代发生错误的那个数据,然后传递给下游
return of(8);
})
)
// 错误被catchError捕获处理,所以此处不存在错误
.subscribe(console.log);注意: 异常函数的第一个参数caught$比较有意思,因为它代表的是上游的 Observable对象,如果异常函数就返回caught$的话,相当于让上游Observable 重新试一遍,所以,catch这个操作符其实不光有恢复的功能,也有重试的功能
=> retry操作符 <= 第一种参数: 直接传一个数字 说明: 它可以让上游的Observable重新试一遍,以达到重试的目的,它接受一个数值参数number,number等于指定重试的次数, 如果number为负数或者没有number参数,那么就是无限次retry,直到上游不再抛出错误异常为止
参数: retry(重试的次数)
注意: retry调用应该有一个正整数的参数,也就是要指定有限次数的重试,否则,很可能陷入无限循环,毕竟被重试的上游Observable只是有可能重试成功,意思就是也有可能重试不成功,如果真的运气不好就是重试不成功,也真没有必要一直重试下去,因为retry通常要限定重试次数,所以retry通常也要和catch配合使用,重试只是增加获得成功结果的概率,当重试依然没有结果的时候,还是要catch上场做恢复的操作
import { range, map, catchError, of, retry } from "rxjs";
const source$ = range(1, 5);
const error$ = source$.pipe(
map((value) => {
if (value === 4) {
throw new Error("unlucky number 4");
}
return value;
})
);
const catch$ = error$
.pipe(
// 重复两次
retry(2),
catchError((err, caught$) => {
return of(8);
})
)
.subscribe(console.log);第二种参数: 传一个配置对象 import { range, map, catchError, of, retry } from "rxjs";
const source$ = range(1, 5);
const error$ = source$.pipe(
map((value) => {
if (value === 4) {
throw new Error("unlucky number 4");
}
return value;
})
);
const catch$ = error$
.pipe(
// 重复两次
retry({
count: 2,
delay: (err$, retryCount) => {
console.log(err$, retryCount);
// 如果这里没有返回值,下面只会出现一次重复
return of(1000);
},
}),
catchError((err, caught$) => {
return of(8);
})
)
.subscribe();=> finalize操作符 <= 说明: 它接受一个回调函数作为参数,上游无论是完结还是出现错误这个函数都会执行,只不过在一个数据流中只会作用一次,同时这个函数也无法影响数据流。
九、多播 说明: 多播就是让一个数据流的内容被多个Observer订阅
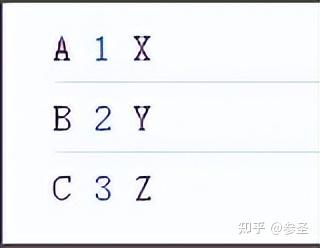
(1)数据流的关系 说明: 这里指的是Observable和Observer的关系,可以理解成前者播放内容,后者接受内容,播放的形式有单播、广播和多播
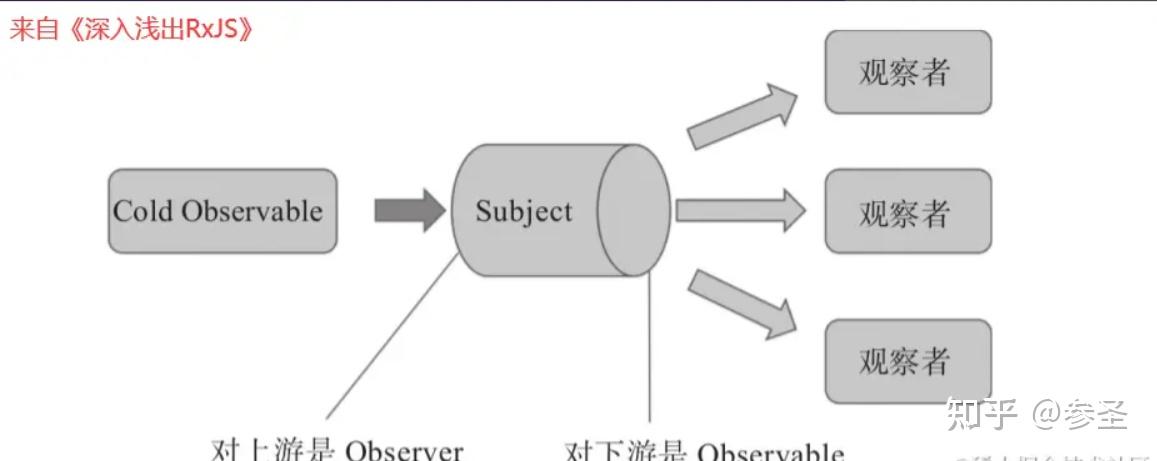
理解概念: (2)Subject 承上启下: 根据第一部分对两种Observable的理解不难得到Cold Observable实现的是单播,Hot Observable实现的多播
问题: 如何把Cold Observable变成Hot Observable呢
解决: 在函数式编程的世界里,有一个要求是保持不可变性,所以,要把一个Cold Observable对象转换成一个Hot Observable对象,并不是去改变这个Cold Observable对象本身,而是产生一个新的Observable对象,包装之前Cold Observable对象,这样在数据流管道中,新的Observable对象就成为了下游,想要Hot数据源的Observer要订阅的是这个作为下游的Observable对象,所以此时需要一个中间人来完成转化,这个中间人就是Subject
中间人的职责: => 双重身份 <= 说明: 这里说的是它具有具Observable和Observer的性质,虽然⼀个Subject对象是一个Observable,但是这两个之间存在区别,区别在于Subject是存在记忆的,也就是它能够记住有哪些Observer订阅了自己,Subject有状态,这个状态就是所有Observer的列表,所以,当调用Subject的next函数时,才可以把消息通知给所有的Observer
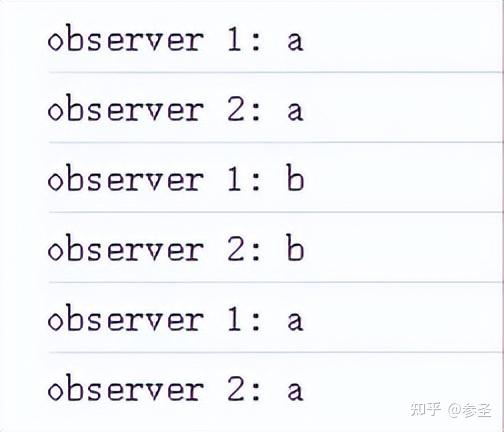
import { Subject } from "rxjs";
const subject = new Subject();
// 1号Observer订阅了subject
const subscription1 = subject.subscribe(
(value) => console.log("on observer 1 data: " + value),
(err) => console.log("on observer 1 error: " + err.message),
() => console.log("on observer 1 complete")
);
// 调⽤subject的next推送了数据1,这个消息只有1号Observer响应,
// 因为当前只有⼀个Observer。同时因为next(1)在2号Observer
// 加⼊之前执⾏,所以2号Observer没有接收到1
subject.next(1);
// 2号Observer也订阅了subject
subject.subscribe(
(value) => console.log("on observer 2 data: " + value),
(err) => console.log("on observer 2 error: " + err.message),
() => console.log("on observer 2 complete")
);
// 这时候调⽤subject的next⽅法推送数据2,subject现在知道⾃⼰
// 有两个Observer,所以会分别推送消息给1号和2号Observer
subject.next(2);
// subject的1号Observer通过unsubscribe⽅法退订
subscription1.unsubscribe();
// 这时候subject知道⾃⼰只有⼀个2号Observer,
// 所以,当调⽤complete⽅法时,只有2号Observer接到通知
subject.complete();特点: 后加入的观察者,并不会获得加入之前Subject对象上通过next推送的数据
实现多播: 既然Subject既有Observable又有Observer的特性,那么,可以让一个Subject对象成为一个Cold Observable对象的下游,其他想要Hot数据源就可以订阅这个Subject对象来达到转换的目的,以此完成多播的操作。
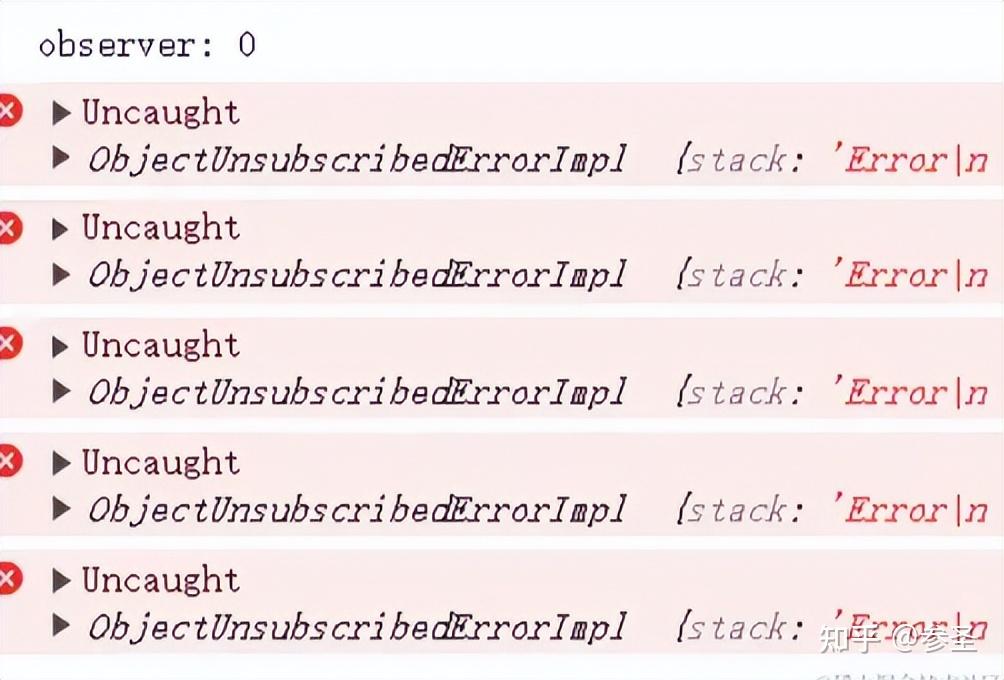
=> 不能重复使用 <= 说明: Subject对象也是一个Observable对象,但是因为它有完结的状态,所以不像Cold Observable对象一样每次被subscribe都是一个新的开始,正因为如此,Subject对象是不能重复使用的,所谓不能重复使用,指的是一个 Subject对象一旦被调用了complete或者error函数,那么,它作为Observable 的生命周期也就结束了,后续还想调用这个Subject对象的next函数传递数据给下游,会没有任何反应。
import { Subject } from "rxjs";
const subject = new Subject();
// ⾸先1号Observer成为subject的下游
subject.subscribe(
(value) => console.log("on observer 1 data: " + value),
(err) => console.log("on observer 1 error: " + err.message),
() => console.log("on observer 1 complete")
);
// 然后通过subject的next函数传递了1和2
subject.next(1);
subject.next(2);
// 紧接着调⽤了subject的complete函数,结束了subject的⽣命周期
subject.complete();
// 2号Observer也成为subject的下游,但是,这时候subject已经完结了
subject.subscribe(
(value) => console.log("on observer 2 data: " + value),
(err) => console.log("on observer 2 error: " + err.message),
() => console.log("on observer 2 complete")
);
// 后续通过next传递参数3的调⽤,不会传递给2号Observer,
// 也不会传递给1号Observer,但是可以获取subject的complete通知,
// 可以这样认为,当⼀个Subject对象的complete函数被调⽤之后,
// 它暴露给下游的Observable对象就是⼀个由empty变量产⽣的直接
// 完结的Observable对象
subject.next(3);注意: 在Subject的生命周期结束之后,再次调用next方法没有任何反应,也不会抛出错误,这样可能会认为上游所有数据都传递成功了,这是不合理的,由于Subject是一个Observable,那么它就会存在一个unsubscribe的方法,表示它已经不管事了,再次调用其next方法就会报错,所以可以像下面这样达到警示的目的。
import { Subject, interval, take } from "rxjs";
// tick$会间隔⼀秒钟吐出数据,调⽤下游subject的next函数
const tick$ = interval(1000).pipe(take(5));
const subject = new Subject();
tick$.subscribe(subject);
subject.subscribe((value) => console.log("observer: " + value));
// 在1.5秒的时候subject的unsubscribe函数被调⽤,
// 所以,2秒以后的时间,tick$还要调⽤subject的
// next就会抛出⼀个错误异常
setTimeout(() => {
subject.unsubscribe();
}, 1500);=> 多个上游 <= 说明: 理论上 可以用一个Subject合并多个Observable的数据流,但是这样做并不合适,原因 在于任何一个上游数据流的完结或者出错信息都可以终结Subject对象的生命。
import { Subject, interval, take, map } from "rxjs";
// 这两个数据流都是通过interval产⽣的Cold Observable对象,
// 每隔⼀秒钟吐出⼀个整数,然后利⽤map转化为间隔⼀秒钟吐出
// ⼀个固定的字符串,利⽤take只从两个数据流中分别拿两个数据
const tick1$ = interval(1000).pipe(
map(() => "a"),
take(2)
);
const tick2$ = interval(1000).pipe(
map(() => "b"),
take(2)
);
const subject = new Subject();
tick1$.subscribe(subject);
tick2$.subscribe(subject);
subject.subscribe((value) => console.log("observer 1: " + value));
subject.subscribe((value) => console.log("observer 2: " + value));
// tick1$每隔⼀秒钟吐出⼀个a字符串,吐出两个之后完结,
// tick2$同样每隔⼀秒钟吐出⼀个字符串,只不过吐出的是b,
// 同样是吐出两个之后完结。因为subject订阅了tick1$和tick2$,
// 所以理论上结果应该是下面这八个值,但其实并不是
// observer 1: a
// observer 2: a
// observer 1: b
// observer 2: b
// observer 1: a
// observer 2: a
// observer 1: b
// observer 2: b理解: 为tick1$是由take产生的,也就是说在吐出2个数据之后就会调用下游的complete函数,也就是调用subject的complete函数,此时它已经完结,后续的next的方法是没有效果的,这也是为什么第二个b不会有效果的原因。
=> 错误处理 <= 说明: 如果Subject有多个Observer,并且Subject的某个下游数据流产生了一个错误异常,而且这个错误异常没有被Observer处理,那这个Subject其他的Observer都会失败,为了避免这种情况的发生,每有一个Observer的时候,就需要给它一个处理错误的地放就可以解决这个问题了。
十、调度器Scheduler (1)作用 作用: 用于控制RxJS数据流中数据消息的推送节奏
举例: 这里以带Scheduler类型的参数的操作符range为例,不过使用调度器的这种写法已经废弃,这里只是举例而已
// 不使用调度器
import { range } from "rxjs";
const source$ = range(1, 3);
console.log("before subscribe");
source$.subscribe(
(value) => console.log("data: ", value),
(error) => console.log("error: ", error),
() => console.log("complete")
);
console.log("after subscribe");解释: 因为range是同步输出数据,所有当Observer添加之后,会把所有数据全部吐出,所以上面的代码也是完全同步执行 的。
// 使用调度器,写法已经废弃
import { range, asapScheduler } from "rxjs";
const source$ = range(1, 3, asapScheduler);
console.log("before subscribe");
source$.subscribe(
(value) => console.log("data: ", value),
(error) => console.log("error: ", error),
() => console.log("complete")
);
console.log("after subscribe");思考: 所以这里的asapScheduler决定了数据推送任务不是同步执行,因为range数据的吐出是在after subscribe字符串之后的,那么什么是Scheduler呢?
RxJS中定义Scheduler: (2)内置的Scheduler 调度器 说明 null 默认不使用,代表同步执行的情况 queueScheduler 利用队列实现,用于迭代操作 asapScheduler 在当前工作之后,下个工作之前执行,用于异步转换 asyncScheduler 用于基于时间的操作 animationFrameScheduler 用于创建流畅的浏览器动画
(3)支持Scheduler的操作符 => observeOn操作符 <= 作用: 根据上游的Observable对象产生出一个新的Observable对象出来,让这个新的Observable对象吐出的数据由指定的Scheduler来控制
参数: observeOn(调度器)
import { range, observeOn, asapScheduler } from "rxjs";
const source$ = range(1, 3);
const asapSource$ = source$.pipe(observeOn(asapScheduler));
console.log("before subscribe");
// 订阅新产生的Observable发现受调度器的影响
asapSource$.subscribe(
(value) => console.log("data: ", value),
(error) => console.log("error: ", error),
() => console.log("complete")
);
console.log("after subscribe");import { range, observeOn, asapScheduler } from "rxjs";
const source$ = range(1, 3);
const asapSource$ = source$.pipe(observeOn(asapScheduler));
console.log("before subscribe");
// 订阅上游数据发现不受调度器的影响
source$.subscribe(
(value) => console.log("data: ", value),
(error) => console.log("error: ", error),
() => console.log("complete")
);
console.log("after subscribe");注意: observeOn只控制新产生的Observable对象的数据推送节奏,并不能改变上游Observable对象所使用的Scheduler
=> subscribeOn操作符 <= 说明: 这个跟observeOn的区别在于前者是控制什么时候订阅Observable对象,而后者是控制Observable对象何时往下游推送数据,使用和参数是类似的。




























































 400 186 1886
400 186 1886


